前端面经笔记
本文最后更新于:2022年5月6日 晚上
遗憾的序
上个月才下定目标,决定找一份前端的工作,在这之前我对我应该选择什么岗位是迷茫的,前端?后端?安全岗?
之前有一段时间因为在实验室里干的远程检测的活觉得自己能找一份安全岗的工作,所以认为自己可以不刷Leetcode,上个月才认清我在实验室干的活就是个脚本小子来就能干的活,没有任何技术含量。
考虑到大学以来的的大一年度计划和大二的科技立项,打CTF也是web方向的,对前端还算比较感兴趣,这才正式下定决心找一份前端的工作。
但是上个月已经是3月了,金3银4,很多人在3月份已经找到实习了,而我才刚刚开始系统的学习。
这一个月来通读了MDN教程,但是没记住多少,看了JS的红宝书《JavaScript高级程序设计(第四版)》,这几天开始看《你不知道的JavaScript》和《css揭秘》。
问了下班里已经找到字节前端实习的BW兄,他给了我一份前端面经,我看了一眼,觉得质量确实不错。遂打算今后每天再看书的时候也要看面经。别再像上周一样在看了0面经的情况下去面试而浪费机会了。
暑期实习可能是找不到了,但是提前批和秋招现在应该还来得及准备。
HTML
1. html 语义化
根据内容来选择合适的标签,将代码语义化,方便开发者阅读,同时提供了SEO和浏览器屏幕阅读器更好的解析。
-
不要滥用 div 和 span
-
弃用纯样式标签。将 b 代替为 strong,i代替为em。u改用css设置下划线。
wuuconix
1
<strong><em>wuuconix</em></strong>
这是一个同时利用strong和em标签的结果。
-
使用表格时,标题用caption 表头用thead,主体用tbody,尾部用 tfoot包裹。增强可读性。【值得注意的是这几个元素不是html5的新元素,但是它们提供了语义信息】
wuuconix's table Header1 Header2 Content1 Content2 Foot1 Foot2 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21<table>
<thead>
<caption>wuuconix's table</caption>
<tr>
<th>Header1</th>
<th>Header2</th>
</tr>
</thead>
<tbody>
<tr>
<td>Content1</td>
<td>Content2</td>
</tr>
</tbody>
<tfoot>
<tr>
<td>Foot1</td>
<td>Foot2</td>
</tr>
</tfoot>
</table> -
表单可以使用fieldset和legend标签增强语义【实际上实际看上去也更清楚了】
1
2
3
4
5
6
7<form>
<fieldset>
<legend>武丑兄的信息</legend>
身高: <input type="text" />
体重: <input type="text" />
</fieldset>
</form>可以看到,fieldset标签会为表单增加一圈边框。而legend标签会在边框上写上一个标题。
-
每个input标签的说明都需要使用label标签,通过为input设置id,label 设置for=id 将label和响应的input关联起来。
所以我们可以改写上面的例子。
1
2
3
4
5
6
7<form>
<fieldset>
<legend>武丑兄的信息</legend>
<label for="height">身高:</label><input type="text" id="height"/>
<label for="weight">体重:</label><input type="text" id="weight"/>
</fieldset>
</form>视觉效果上实际上一摸一样的,但是将label和input进行绑定后,我们点击label的文字,对应的input会获得焦点,优化用户体验。
-
html5新的语义化标签速记。nav header main aside footer article section 等等。
大部分语义标签只是提供语义,本身没有什么特别的,而html5新增的 summary 和 details 即提供了语义又在视觉效果、实用性方面很赞。它可以将某些标签隐藏。
武丑兄的图片
1
2
3
4<details>
<summary>武丑兄的图片</summary>
<img src="https://url.wuuconix.link/favicon">
</details>其中details用来指明内部的标签需要被折叠起来。而summary给了内部内容一个概括。这种不用js实现的折叠效果真的很赞。
2. canvas 相关
在使用canvas之前,我们需要确保先得到一个2d的上下文环境。
具体的咱也不会,就记住一些比较基础的函数吧。
1 | |

3. svg和canvas的区别?
- canvas是html5提供的新的绘图方式。svg基于xml,已经发展了20多年。
- canvas基于位图,缩放会失真。svg是矢量图形,缩放不会失真。
- canvas需要在js中绘制,而svg在html中绘制。
- canvas支持的颜色比svg多。
- canvas无法对已经绘制的图像进行修改,操作;svg可以获取到标签进行操作。
4.html5有哪些新特性?
HTML5增加了许多实用的API和标签。
-
拖拽释放 Drag and drop API,在上传文件的情景中十分常见。
-
新增了许多语义标签,比如 nav, header, main, aside, footer, article, section等等。
-
Audio、Video API,让html5能够不依赖flash等插件的情况下播放音频、视频。
-
画布 Canvas API,可以让开发者绘制复杂的图形。
-
地理 Geolocation API,获得设备的位置信息、速递信息。
-
localStorage 可以用来长期存储数据,浏览器关闭后不丢失。sessionStorage 在浏览器关闭后自动删除。
-
表单空间里新增了许多实用的类型。比如 url, email, search, date, time search 等等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14<form>
<fieldset>
<legend>测试控件</legend>
<input type="email" placeholder="email"><br>
<input type="url" placeholder="url"><br>
<input type="date" placeholder="date"><br>
<input type="time" placeholder="time"><br>
<input type="color" placeholder="color"><br>
<input type="range" placeholder="range"><br>
<input type="search" placeholder="search"><br>
<input type="password" placeholder="password"><br>
<input type="reset"><input type="submit">
</fieldset>
</form>其中email和url会对用户的输入进行正则匹配,比如邮件中肯定需要@。至于它们的提示是在点击提交后才产生的,用户输入过程中则没有提示。
还有一些以前难以想象的input控件,比如 date用来选择日期,time用来选择具体时间。color用来选择颜色,range用来滑动选择比例,现代的网页设计真的是十分方便了。
至于search,我猜测应该是会调用起浏览器的历史输入框,以展示用户之前输入过的内容?可能由于没有后端支持的原因,纯前端测试没有效果。
password可以让输入文本变成 * ,起到防偷窥密码的目的。
5.如何处理HTML5新标签的浏览器兼容问题?
IE8/IE7/IE6可以用document.createElement方法来产生框架,这样可以让浏览器支持html5新标签。【这IE什么离谱的设定】
更好的方式是直接使用成熟的框架,比如html5shiv 【现在HTML5已经大范围普及了,这个项目也已经7年不更新了,希望面试官不会再问这种不合时宜的问题】
6. 说说 title 和 alt 属性
- alt是img的特有属性,是当图片内容的等价描述,图片无法正常显示时的替代文字。大部分浏览器在鼠标悬停在图片上时不会显示出alt的内容【貌似IE会在悬停时展现出alt的内容】
- title属性可以用在非常多的标签上,是对dom元素的一种类似注释说明。鼠标悬停在那个元素上时会展现出title的内容跟。

1 | |
7.HTML全局属性(global attribute)有哪些
- class 为元素设置类表示。
- data-* 用来为元素增加自定义属性。
- draggable 设置元素是否可以拖拽
- contenteditable 设置元素是否可以让用户以所见即所得的方式更改
- id 元素ID,文档内唯一
- lang 元素内容的语言
- style 行内css样式
- title 元素相关注释信息
- hidden 设置元素是否隐藏
- 等等
我拿其中比较有意思的contendeditable举个例子,将它设置为true可以让元素变成一个WYSIWYG的编辑器。
wuuconix yyds--- Write Your Name Here
1 | |
CSS
1. 让一个元素水平垂直居中,到底有多少种方案?
这个问题我们将题目简化为两个问题。如何将元素设置水平居中 以及 如何将元素设置为垂直居中。
水平居中:
-
如果是内联元素/行内元素,比如 p 标签 直接
text-algin: center即可行内元素水平居中
1
<p style="text-align:center; background-color:greenyellow; color:black">行内元素水平居中</p> -
如果是块级元素,比如我们常见的 div 标签,将左右外边距设置为auto即可。
左右边距auto实现块级元素水平居中1
<div style="margin:5px auto; width:300px; height:32px; background-color:aquamarine; text-align: center; color:black">左右边距auto实现块级元素水平居中</div>这里需要解释一下,margin实际上是一个简写属性,它在写两个值的时候,第一个值指定上下外边距,第二个值指定左右外边距,所以我们这里是将左右外边距设置为了auto 实现水平居中。
-
块级元素 绝对定位 + 负左边距实现水平居中
绝对定位+负左边距实现水平居中1
2
3<div style="position: relative; height: 40px;">
<div style="position:absolute; left:50%; margin-left:-150px; width:300px; height:32px; background-color:black; text-align:center; color:white">绝对定位+负左边距实现水平居中</div>
</div>由于需要用要绝对定位,我们需要在它之前添加一个定位为relative的父元素,这样可以不捣乱之后的元素。这里我们首先把left 设置为了父元素的50%,实际上是子元素的左边界处于中线位置,而我们需要的是子元素的中线在中线位置,所以我们利用负左外边距的技术让子元素往左移动,实现居中。margin-left的值是负的子元素的宽度。所以这种方法需要知道子元素的宽度。
-
块级元素 绝对定位 + translateX实现水平居中
绝对定位+translateX实现水平居中1
2
3<div style="position: relative; height: 40px;">
<div style="position:absolute; left:50%; transform:translateX(-50%); width:300px; height:32px; background-color:darkorange; text-align:center;color:black">绝对定位+translateX实现水平居中</div>
</div>这种方法和上一种方法类似,首先都是绝对定位,把子元素的左界顶着中线,上一种方法是利用负左外边距实现居中,这种方法直接使用
transform: translateX(-50%)把自己往左移动自己宽度的一半,实现居中。由于这里直接利用了子元素宽度的百分比,所以不需要知道实际宽度,比上一种方法实用度更广。 -
块级元素 父元素设置flex布局实现水平居中
父元素设置flex布局实现水平居中1
2
3<div style="display:flex; justify-content:center;">
<div style="width:300px; height:32px; background-color:blueviolet; text-align:center;color:white">父元素设置flex布局实现水平居中</div>
</div>flex布局真的很强,子元素实际上没有设置任何有效属性。父元素设置成flex布局,一个
justify-content:center直接水平居中。
接下去我们看看垂直居中
-
如果是父块元素中的一行 内联元素/行内元素,比如 span 标签,我们直接将行高设置为父块元素的高度即可。
wuuconix yyds1
2
3<div style="line-height:50px; text-align:center; height:50px; border:5px dotted violet;">
<span>wuuconix yyds</span>
</div>当然了,我们都把行高设置成这么大了,这只适用于文字量很少,只有一行的情况下,如果有两行的话,第二行就会到父div外面。
-
父子块级元素 绝对定位 + 负外边距实现垂直居中
绝对定位+负外边距实现垂直居中1
2
3<div style="position:relative; height: 50px; border: 5px dotted violet">
<div style="position:absolute; top:50%; left:50%; margin-left:-150px; margin-top:-16px; width:300px; height:32px; background-color:indianred; text-align:center; line-height:32px;color:white">绝对定位+负外边距实现垂直居中</div>
</div>由于处于好看考虑,这里在实现垂直居中的同时顺手都实现了水平居中。绝对定位 + 负外边距的技术和之前水平居中的3号方法一致,不过多介绍。这次多提一嘴,这个实例中实际上包含两个垂直居中。第一个父div和子div的垂直居中,利用绝对定位+负外边距技术,还有一个是子div和里面的textContent的垂直居中,利用了1号行高的方法。
-
父子块级元素 绝对定位 + transform:translateY(-50%) 实现垂直居中
绝对定位+translateY实现垂直居中1
2
3<div style="position:relative; height: 50px; border: 5px dotted violet">
<div style="position:absolute; top:50%; left:50%; transform:translateY(-50%) translateX(-50%); width:300px; height:32px; background-color:brown; text-align:center; line-height:32px;color:white">绝对定位+translateY实现垂直居中</div>
</div>和水平居中4号方法同理,不赘述。
-
父子块级元素 绝对定位 + top:0; bottom:0 + 上下auto实现垂直
绝对定位+top:0;bottom:0+上下auto实现垂直居中1
2
3<div style="position:relative; height: 50px; border: 5px dotted violet">
<div style="position:absolute; top:0; bottom:0; left:0; right:0; margin:auto; width:300px; height:32px; background-color:darkgoldenrod; text-align:center; line-height:32px;color:white">绝对定位+top:0;bottom:0+上下auto实现垂直居中</div>
</div>这个方法很妙,着重讨论一下。首先它基于绝对定位,然后我们将 top和bottom都设置为了0,这实际上是很奇怪的,因为这意味着子div元素顶部和底部都应该紧贴着父元素,但是这貌似是不可能的,因为子元素的高度小于父元素的高度。但是我们这里又设置了
margin:auto,这会发生什么效果呢?浏览器将自动设置合适的外边距,让子元素顶着父元素,最终实现了垂直居中的效果。实际上这种思想也完全适用于水平居中【实际上这个例子里也是这样实现水平居中的】 -
父子块元素 父flex+子全auto实现垂直居中
父flex+子全auto实现垂直居中1
2
3<div style="display:flex; position:relative; height: 50px; border: 5px dotted violet">
<div style="margin:auto; width:300px; height:32px; background-color:hotpink; text-align:center; line-height:32px">父flex+子全auto实现垂直居中</div>
</div>flex布局总是带给我们惊喜,回顾一下我们的4号方法,margin: auto的妙处。我们需要将top和bottom全部设置为0才能实现垂直居中。但是看这个实例,我们只需要将父元素设置为flex布局,然后子元素啥都不用干,也不用设置绝对定位,只需要优雅的使用 margin: auto,一切将水到渠成。
-
父table子table-cell 利用 verticle_align 垂直居中
父table子table-cell垂直居中1
2
3<div style="display:table; height: 50px; border: 5px dotted violet; width: 100%">
<div style="display:table-cell; vertical-align:middle; width:300px; height:32px; background-color:darkseagreen; text-align:center; color: black">父table子table-cell垂直居中</div>
</div>我们的目的是我们已经听到很久的属性
vertical-align,听这名字我们就知道它生来为了垂直居中。但是可惜的是,它的使用及其严格,首先父元素需要时是一个table,然后子元素是table-cell或者是一个内联元素。该例子演示的是一个 table-cell的情况。值得注意的是,转化为table-cell后貌似产生了副作用,如你所看到的,子元素的长和宽都被拉到的父元素的长宽。 -
父table子内联元素/行内元素 利用 vertical_align 垂直居中
父table子内联元素/行内元素实现垂直居中
1
2
3<div style="display:table; height:50px; border:5px dotted violet; width: 100%">
<p style="vertical-align:middle; background-color:aqua; text-align:center; color:black">父table子内联元素/行内元素实现垂直居中</p>
</div>和6同理。只不过因为 p 本来就是内联元素,不是块元素,不需要转化为 table-cell,没有宽和长被拉伸的问题。
2. 浮动布局的优点?有什么缺点?清除浮动有哪些方式?
浮动产生于标准流布局方式的局限。在标准流或者普通流中。块级元素会独占一行,然后上下排列。比如<br>和<p>,没错 p 也是一个块级元素,它也可以设置高度和宽度。 而内联元素 / 行内元素则会从左到右排序,碰到父元素边界则会自动换行。 比如 <span>和<a>等。
但是要我说,最常见的内联元素实际上就是普通的文本,比如 p 里面包裹的内容,它们就是内联元素,这也是为什么 p 能够用 text-align 来水平居中它们的原因
标准流很好,简洁易懂,但是人们在追求更加好看的网页设计的时候想更上一层楼,首先遇到的第一个问题就是两个块级元素 在同一行内显示的问题。我们这里拿两个<img>举例子。正常情况下它们将出现在两行。加上display: inline-block貌似就能解决这个问题。
display:inline_block实现两个块级元素在同一行中
1 | |
这看上去非常不错。但是我们注意到一个奇怪的情况,就是两个图片之间貌似隔了点距离?虽然在这里这个距离刚刚好,但是在某些情况下你会被这个间距搞疯的。实际上这个间距来源于两个标签之间的换行。如果我们取消换行,这个间距就消失了。然而这会使代码可读性变差。
把两个img连着写可以取消缝隙
1 | |
如果我们用float来实现就不会有这个缝隙。
float将没有缝隙
1 | |
所以到这里我们可以写下浮动的优点了:
-
可以将多个块级元素在同一行里显示,在一些图文混排的场景里很常见。
-
与inline-block类似,但是它比inlne-block有两个好处,横向排序的时候float可以选择方向而inline-block不行,float还可以避免使用inline-block出现的缝隙问题。
但是浮动也有一个很大的问题,最常见的就是如果父元素没有设置高度,而子元素设置了高度,在标准流中,父元素将被撑起来,而在子元素被设置为浮动后,父元素的高度将变成0,俗称父元素高度塌陷。
这里举一个例子。父元素使用边框来明确它的位置。
标准流的情况 父元素的高度被撑起
1 | |
子元素设置float后 父元素高度坍缩
1 | |
我们如何解决这个问题呢?这就需要消除浮动。消除浮动有两种办法。
-
在父元素设置
overflow: hidden取消浮动。1
2
3
4<div style="overflow:hidden; border: yellowgreen dashed 3px; width:150px; margin: 5px auto">
<img style="float:left" src="https://url.wuuconix.link/favicon" width="150px">
<p style="float:left; text-align:center">父元素设置overflow取消浮动</p>
</div>这看起来挺奇怪的,为什么设置这个属性后就清除了浮动了呢?查询过资料后,设置overflow为hidden将触发BFC (Block Formatting
context) 格式化上下文。而BFC的一大功能就是清除浮动。其次我们仔细阅读MDN关于BFC的链接可以知道,只要把
overflow设置为visible以外仍以的值就能触发BFC,比如auto, hidden, scroll都能实现清除浮动的效果。 -
第1种方法依赖触发BFC,比较玄学,不太好理解。更好理解的方法是在最后一个浮动的元素后面加上一个空元素,并且设置属性
clear:both。手动写一个空元素清除浮动
1
2
3
4
5<div style="border: yellowgreen dashed 3px; width:150px; margin: 5px auto">
<img style="float:left" src="https://url.wuuconix.link/favicon" width="150px">
<p style="float:left; text-align:center">手动写一个空元素清除浮动</p>
<div style="clear:both"></div>
</div> -
第2种方法看起来挺简单也好理解,但是额外的标签,容易让html结构混乱。所以我们可以使用css中的伪类
::after来加一个空元素。伪类after优雅清除浮动
1
2
3
4
5
6
7
8
9
10
11
12
13<style>
.outter::after {
content: "";
display: block;
clear: both;
height: 0;
visibility: hidden;
}
</style>
<div class="outter" style="border: yellowgreen dashed 3px; width:150px; margin: 5px auto">
<img style="float:left" src="https://url.wuuconix.link/favicon" width="150px">
<p style="float:left; text-align:center">伪类after优雅清除浮动</p>
</div>这里解释一下伪类
::after是什么意思,我们可以看到这里是被添加在父元素上的,它的作用实际上就是在父元素内部的最后元素后面再添加一个元素,而我们这里把伪类设置成了块元素,然后清除了浮动了,为了让它彻底隐形,我们还设置了其他的一些属性。
然后因为内联css无法添加伪类,这里使用了style标签。
3. 使用display:inline-block会产生什么问题?解决方法?
这个问题在2. 浮动布局的优点?有什么缺点?清除浮动有哪些方式?里面就讲过了。两个inline-block并排中间会有缝隙。
它产生缝隙的原因
元素被当成行内元素排版的时候,元素之间的空白符(空格、回车换行等)都会被浏览器处理,根据CSS中white-space属性的处理方式(默认为normal,合并多余空格),html代码中的回车被转化为一个空白符,在字体不为0的情况下,空白符占据一定宽度,所以就出现了缝隙。
解决方法
-
写标签时不换行。【强迫症的噩梦】
-
父元素设置
font-size: 0,在子元素上重新设置正确的font-size。1231231
2
3
4<div style="font-size:0; text-align: center;">
<div style="font-size: 16px; display: inline-block; width: 150px; background-color: violet; color:white">123</div>
<div style="font-size: 16px; display: inline-block; width: 150px; background-color: hotpink; color:white">123</div>
</div>这个方法很妙,把中间的空白元素的字体设置为零。
-
使用float布局,具体参考 2. 浮动布局的优点?有什么缺点?清除浮动有哪些方式?
4. 布局题:div垂直居中,左右10px,高度始终为宽度一半
题目描述:实现一个div垂直居中, 其距离屏幕左右两边各10px, 其高度始终是宽度的50%。同时div
中有一个文字A,文字需要水平垂直居中。
这道题看起来比较简单,就是一个div在窗口内垂直居中,然后这个div内部一个文字A垂直水平居中。但是它有一个奇怪的条件,让div的高度始终时宽度的50%。这貌似是无法达成的,因为CSS中可没有变量这种东西,宽度是会变的,而高度的值需要来自于一个变量,这很奇怪。
有两个方法可以解决这个看似无解的问题。
-
我们用
height:0; padding-bottom:50%这个黑科技来实现。因为
padding-bottom的百分比是基于父元素的width来的,我们让div的 content的高度为0,而用下内边距来实现把高度设置为宽度的一半。A1
2
3
4
5<div style="height: 100%; margin: 0 10px; display: flex; align-items: center">
<div style="height: 0; padding-bottom: 50%; width: 100%; background-color: orange; position: relative">
<div style="position: absolute; width: 100%; height: 100%; display: flex; justify-content: center; align-items: center">A</div>
</div>
</div>可以看到,为了实现效果我们用了三层div。实际的效果是由第二层div完成 “实现一个div垂直居中, 其距离屏幕左右两边各10px, 其高度始终是宽度的50%” 的要求。第三层div完成 “同时div中有一个文字A,文字需要水平垂直居中” 的要求。
因为第二层div要求垂直居中,我们便在它外面加了一层div设置flex布局从而设置垂直居中。此外最外层的div还实现了左右10px外间距的要求。
我们注意到最里层div 还设置为了绝对定位,这有什么作用呢?按理说最里层div只需要设置flex布局就可以十分轻松的把文字A垂直水平据中。这是因为如果不设置绝对定位,最里层div的 height 的百分比是只有 父元素即第二层div 的
Content-Box的高度的,而第二层由于要实现高度是宽度的一半的效果,将 height设置为了0,所以按理说最里层div 的height设置的百分比怎么设置最后的值都是0。这就没法实现垂直居中了!好在另一个黑科技拯救了我们,即当子元素设置为绝对定位时,height的百分比将 为
Padding-Box,即包含了内边距,这样我们就能得到真正的高度了! -
用上面这种黑科技实现了目的,但是我们的代价也是很大了,为了使用 padding-bottom ,最里层的div元素还需要设置绝对定位来得到包含内边距的高度。其实利用CSS里面强大的单位
vw就能优雅的解决这个问题而不使用任何黑科技。vw和vh为相对应 1vh 意味着值为视口高度的 1%,1vw 即值为视口宽度的 1%。有了vw这个强大的单位我们非常容易就能达成高度是宽度的一半这个条件了!只需要设置
heihgt: 50vw。1
2
3<div style="width: 100%; heihgt: 100%; position: relative">
<div style="margin: 0 10px; width: calc(100vw - 20px); height: 50vw; position: absolute; top: 50%; transform: translateY(-50%); display: flex; justify-content: center; align-items: center; background-color: darkorange">A</div>
</div>可以看到这种方法让结构简单了许多,只有两层div了。
由于直接使用视窗的百分比,直接放在博客里的话就溢出文章了。所以这里的演示实际上用了iframe,实际的页面在 https://wuuconix.github.io/static/magic-vh.html
5. 盒模型
有两种盒模型,分别是 W3C标准盒模型 和 IE盒模型。
它们的区别在于对宽度和高度的定义。但是它们盒子的组成部分实际上都是一样的,即 Content-Padding-Border-Margin。

它们元素的最终宽度和高度都是一样的,即Content+Padding+Border。
在浏览器里用元素审查 查看元素的宽和高 不包括margin。所以这里把元素的最终高度看作这三者之和。
唯一的区别在于width 和 height。我们知道,对于块级元素我们是可以设置宽高的。对于标准盒模型,width代表的是content的宽度,至于另外设置padding和border那是另外算,所以最终的元素的实际宽度可能会大于 width的设定值。
而IE盒模型的width指的是 content + padding + border的值。所以按照之前对最终宽高的定义,IE盒模型定义的width便是元素最终的宽高。实际上感觉也是非常方便的,并不像别人说的那么怪异。
在CSS中可以利用 box-sizing: content-box / border-box 来切换两种盒子模型。浏览器默认使用 content-box 标准盒模型。
下面给出两种模型在width都设置为500px,height都设置为32px,设置内边距5px和边框5px的外观比较。
可以看到IE盒模型另设padding和border后总宽度和宽度保持不变,标准盒模型因为是在content的基础再再加,所以比起来大了许多。
6. CSS如何进行品字布局?
品字型布局 局如其字,不多说,直接放效果。
-
如果是全屏的品字形。
1221
2
3<div style="width: 100%; height: 32px; line-height: 32px; text-align: center; background-color: coral">1</div>
<div style="float: left; width: 50%; height: 32px; line-height: 32px; text-align: center; background-color: cornflowerblue;">2</div>
<div style="float: left; width: 50%; height: 32px; line-height: 32px; text-align: center; background-color: hotpink;">2</div>底下两个div因为要放到一起,利用了float布局。
-
如果把每个div都设置为100px的正方形,会麻烦一些。
1231
2
3<div style="width: 100px; height: 100px; margin-left: 50%; transform: translateX(-50%); line-height: 100px; text-align: center; background-color: chartreuse; color: black">1</div>
<div style="float: left; width: 100px; height: 100px; margin-left: 50%; transform: translateX(-100%); line-height: 100px; text-align: center; background-color: darkred; color: white">2</div>
<div style="float: left; width: 100px; height: 100px; transform: translateX(-100%); line-height: 100px; text-align: center; background-color: cornflowerblue; color: white">3</div>从这里我们可以学习到两个新知识点:我们一般水平居中的时候可能会利用
top: 50%; transform: translateX(-50%)的方法,但是这样做首先需要设置为绝对定位。但是可以看到这里的第一个div利用了margin-left: 50%; transform: translateX(-50%);,利用margin-left的方式来把自己div的左边界顶到中心线上,而设置左外边界是不需要设置绝对定位的,十分优雅。第二个知识点是 一个div transform后,后面的元素貌似还是会认为它在本来的位置,这也是为什么第三个div还需要 transform的原因,按理说直接
float: left就ok了。 下面是取消第三个div变形后的结果。123这就好像div2 仍然在那个地方。
7. CSS如何进行圣杯布局
-
圣杯布局用flex来实现是非常简单的,只需要将左右两块设置好宽度后将所有的剩余空间分配给中间的元素。
头部左侧flex右侧尾部1
2
3
4
5
6
7<div style="width: 100%; height: 32px; background-color: palevioletred; display: flex; justify-content: center; align-items: center; color: white">头部</div>
<div style="width: 100%; height: 32px; display: flex; justify-content: space-between; align-items: center;">
<div style="width: 100px; height: 100%; background-color: dodgerblue; display: flex; justify-content: center; align-items: center; color: white">左侧</div>
<div style="flex: 1; height: 100%; background-color: lightgreen; display: flex; justify-content: center; align-items: center; color: black">flex</div>
<div style="width: 100px; height: 100%; background-color: dodgerblue; display: flex; justify-content: center; align-items: center; color: white">右侧</div>
</div>
<div style="width: 100%; height: 32px; background-color: palevioletred; display: flex; justify-content: center; align-items: center; color: white">尾部</div>这段代码真就全员flex布局了。div里面文字的居中也用到了flex布局,实际上只要设置行高+text-align就行,但是flex真的是会用上瘾的,希望它没有滥用一说。
值得注意的是,中间一行的关键div中,justify-content的属性设置为了
space-between,它可以让第一个元素与行首对齐,最后一个元素与行尾对齐。当然这里实际上设置啥值都行,因为宽度被占满了,因为有flex:1。而如果中间没有那个div,space-between的效果就出现了。头部左侧右侧尾部 -
第二种方法是使用简单版float布局,为什么说它简单呢?因为只需要分别设置左侧为
float: left,右侧为float: right,中间的元素直接width: 100%即可,因为float的元素是脱离标准流的。头部尾部1
2
3
4
5
6
7<div style="width: 100%; height: 32px; background-color: palevioletred; line-height: 32px; text-align: center; color: white">头部</div>
<div style="width: 100%; height: 32px;">
<div style="float: left; width: 100px; height: 32px; background-color: dodgerblue; line-height: 32px; text-align: center; color: white">左侧</div>
<div style="float: right; width: 100px; height: 32px; background-color: dodgerblue; line-height: 32px; text-align: center; color: white">右侧</div>
<div style="width: 100%; height: 32px; background-color: lightsalmon; line-height: 32px; text-align: center; color: white">float</div>
</div>
<div style="width: 100%; height: 32px; background-color: palevioletred; line-height: 32px; text-align: center; color: white">尾部</div>这里需要注意的是,中间的div由于没有使用float布局,它需要被放在最后,如果按照普通的写法,把它放在中间,那么右侧的div会放不下而到下一行。
头部左侧float右侧尾部1
2
3
4
5
6
7
8<div style="width: 100%; height: 32px; background-color: palevioletred; line-height: 32px; text-align: center; color: white">头部</div>
<div style="width: 100%; height: 32px;">
<div style="float: left; width: 100px; height: 32px; background-color: dodgerblue; line-height: 32px; text-align: center; color: white">左侧</div>
<div style="width: 100%; height: 32px; background-color: lightsalmon; line-height: 32px; text-align: center; color: white">float</div>
<div style="float: right; width: 100px; height: 32px; background-color: dodgerblue; line-height: 32px; text-align: center; color: white">右侧</div>
<div style="height: 0; clear: both;"></div>
</div>
<div style="width: 100%; height: 32px; background-color: palevioletred; line-height: 32px; text-align: center; color: white">尾部</div>可以这么说,不浮动的元素将无视浮动的元素,因为浮动的元素已经 “浮起来了” 。而浮动元素在浮动时会收到非浮动元素的影响,可以这么想,它们一开始都还没有浮起来,然后根据float设置的不同,去顶着不同的界后再上浮。
因为
右侧div需要顶着右界,而中间div已经占满了哪一行,右侧div被迫换行顶着右侧的边界,再上浮。 -
使用绝对定位布局。由于块级元素如果不使用flex、float或者不转化为inline-block等,正常情况下是分行的。但是如果使用绝对定位,也可以打破这个规则。我们将中间的三个div全部设置为绝对定位。
头部左侧绝对定位右侧尾部1
2
3
4
5
6
7<div style="width: 100%; height: 32px; background-color: palevioletred; line-height: 32px; text-align: center; color: white">头部</div>
<div style="width: 100%; height: 32px; position: relative">
<div style="position: absolute; left: 0; width: 100px; height: 32px; line-height: 32px; text-align: center; color: white; background: dodgerblue">左侧</div>
<div style="position: absolute; left: 100px; width: calc(100% - 200px); height: 32px; line-height: 32px; text-align: center; color: white; background: darkcyan">绝对定位</div>
<div style="position: absolute; right: 0; width: 100px; height: 32px; line-height: 32px; text-align: center; color: white; background: dodgerblue">右侧</div>
</div>
<div style="width: 100%; height: 32px; background-color: palevioletred; line-height: 32px; text-align: center; color: white">尾部</div>绝对定位的思路是设置左侧div
left: 0以及右侧divright: 0,中间的元素就设置left: 100px; width: calc(100% - 200px)或者left: 100px; right: 100px。 -
最后介绍的实现方法是利用
grid布局,它是CSS原生网格布局,简洁优雅又强大。头部左侧享受grid布局吧!右侧尾部1
2
3
4
5
6
7<div style="display: grid; grid-template-rows: repeat(3, 32px); grid-template-columns: 100px calc(100% - 200px) 100px;">
<div style="grid-column: 1 / -1; grid-row: 1 / 2; background-color: palevioletred; color: white; line-height: 32px; text-align: center">头部</div>
<div style="grid-column: 1 / 2; grid-row: 2 / 3; background-color: dodgerblue; color: white; line-height: 32px; text-align: center">左侧</div>
<div style="grid-column: 2 / 3; grid-row: 2 / 3; background-color: paleturquoise; color: black; line-height: 32px; text-align: center">享受grid布局吧!</div>
<div style="grid-column: 3 / -1; grid-row: 2 / 3; background-color: dodgerblue; color: white; line-height: 32px; text-align: center">右侧</div>
<div style="grid-column: 1 / -1; grid-row: 3 / -1; background-color: palevioletred; color: white; line-height: 32px; text-align: center">尾部</div>
</div>可以看到,这次头部、左侧、中间、右侧、尾部变成了并列的兄弟元素,因为它们同在同一个网格中,我们将最外层的包裹div设置为grid布局,同时设置3行3列,每一行的高度都是32px,列则不一样,第一列和第三列是100px,第二列是
calc(100% - 200px)。这个网格列数一设置后,哪些应该放哪里已经一清二楚了。
8. CSS如何实现双飞翼布局?
我看了一下,双飞翼布局和圣杯布局几乎没有区别,主要特点都是左右两个div固定宽度,中间那个div自适应,如果面试遇到了直接按照 7. CSS如何进行圣杯布局 来答就行。
9. 什么是BFC?
BFC我们之前在用overflow:hidden清除浮动的时候见过。
它的全称是 Block Formatting Context 翻译为 块格式上下文
MDN-zh-CN: 它是块盒子的布局过程发生的区域,也是浮动元素与其他元素交互的区域
MDN-en-US: It’s the region in which the layout of block boxes occurs and in which floats interact with other elements.
10. BFC触发条件
以下触发条件来自于MDN
-
根元素 即 html标签
-
浮动元素 float不为none的元素
-
绝对定位元素 元素的的position为 absolute / fixed
-
行内块元素 display: inline-block
-
表格单元格 display: table-cell
-
表格标题 display: table-caption
-
匿名表格单元格元素 display: table / table-row / table-row-group / table-header-group / table-footer-group / inline-table。
值得注意的是inline-table之前的这些display分别是 table, row, tbody, thead, tfoot的默认属性。
结合5,6,7条,我们貌似可以这样记忆,和table相关的所有东西都会触发BFC。
-
overflow 不为 visible的块元素。
-
display 为 flow-root的元素。
一个新的 display 属性的值,它可以创建无副作用的 BFC。在父级块中使用 display: flow-root 可以创建新的 BFC。
给 div 设置 display: flow-root 属性后,div 中的所有内容都会参与 BFC,浮动的内容不会从底部溢出。
关于值 flow-root的这个名字,当你明白你实际上是在创建一个行为类似于根元素 (浏览器中的html元素) 的东西时,就能发现这个名字的意义了——即创建一个上下文,里面将进行 flow layout
-
contain: layout / content / paint 的元素
contain 属性允许开发者声明当前元素和它的内容尽可能的独立于 DOM 树的其他部分。这使得浏览器在重新计算布局、样式、绘图、大小或这四项的组合时,只影响到有限的 DOM 区域,而不是整个页面,可以有效改善性能。
contain: conetent 等价于 contain: layout paint
contain: layout 表示元素外部无法影响元素内部的布局,反之亦然。【大概就是内网元素互补影响布局】
contain: paint 表示这个元素的子孙节点不会在它边缘外显示。如果一个元素在视窗外或因其他原因导致不可见,则同样保证它的子孙节点不会被显示。
-
弹性元素 display: flex 或者 inline-flex元素的直接子元素
-
网格元素 display: grid 或者 inline-grid元素的直接子元素
-
多列容器 【元素的column-count 或者 content-width 不为auto,设置为1也算多列容器】
多列容器不是网格里的多列,而是一个我之前从来没有用过的属性,利用
column-count可以轻松得将一个div分成三列,非常适和文字很长得情况下进行分列。在过去的几年里,CSS 经历了一场巨变,正如 JavaScript 在 2004 年前后所经历的那场革命。它从一门极度简单、功能有限的样式语言,发展成为一项由 80 多项 W3C 规范(含草案)所定义的复杂技术,并建立起了独有的开发者生态圈、专属的技术会议、专用的框架和工具链。CSS 已经如此壮大,以致于一个普通人已经无法把它完整地装进自己的头脑了。甚至在W3C 专门定义这门语言的工作组中,也没人敢说自己是精通 CSS 所有方面的专家,甚至连接近这个程度都非常困难。实际上,大多数工作组成员只专注 CSS 的某个特定细节,可能对其他部分知之甚少。1
2
3<div style="column-count: 3; background-color: bisque; color: black">
在过去的几年里,CSS 经历了一场巨变,正如 JavaScript 在 2004 年前后所经历的那场革命。它从一门极度简单、功能有限的样式语言,发展成为一项由 80 多项 W3C 规范(含草案)所定义的复杂技术,并建立起了独有的开发者生态圈、专属的技术会议、专用的框架和工具链。CSS 已经如此壮大,以致于一个普通人已经无法把它完整地装进自己的头脑了。甚至在W3C 专门定义这门语言的工作组中,也没人敢说自己是精通 CSS 所有方面的专家,甚至连接近这个程度都非常困难。实际上,大多数工作组成员只专注 CSS 的某个特定细节,可能对其他部分知之甚少。
</div>column-count会根据被分配到的宽度自动设置每列的宽度,列数是确定的。column-width则会保证每列的宽度,所以具体的列数会改变。大约在 2009 年之前,评判一个人的 CSS 专业程度并不是看他对这门语言的了解有多深。对当时的 CSS 行业来说,这或多或少就是现实:一个人能否称得上 CSS 高手,往往要看他能记住多少个浏览器 bug 和相应的对策。一转眼就到了 2015 年,现在的浏览器都是以 Web 标准作为设计基准的,过去那些针对特定浏览器的脆弱 hack 早已风光不再。当然,某些不兼容的情况仍然无法避免,但是迭代速度已经非常之快(尤其是因为现在的浏览器几乎都已经实现自动更新了),把这些不兼容的情况记录在书中完全是在浪费时间和空间。1
2
3<div style="column-width: 100px; background-color: lightcyan; color: black">
大约在 2009 年之前,评判一个人的 CSS 专业程度并不是看他对这门语言的了解有多深。对当时的 CSS 行业来说,这或多或少就是现实:一个人能否称得上 CSS 高手,往往要看他能记住多少个浏览器 bug 和相应的对策。一转眼就到了 2015 年,现在的浏览器都是以 Web 标准作为设计基准的,过去那些针对特定浏览器的脆弱 hack 早已风光不再。当然,某些不兼容的情况仍然无法避免,但是迭代速度已经非常之快(尤其是因为现在的浏览器几乎都已经实现自动更新了),把这些不兼容的情况记录在书中完全是在浪费时间和空间。
</div> -
column-span: all 的元素将始终创建一个新的BFC,即使该元素没有包裹在一个多列元素之中。
column-span:all会在父元素设置列数,比如column-count: 3的时候横跨三行。我们在现代 CSS 中所面临的挑战已经不在于如何绕过这些转瞬即逝的浏览器 bug。
如今的挑战是,在保证 DRY1①、可维护、灵活性、轻量级并且尽可能符合标准的前提下,把我们手中的这些 CSS 特性转化为网页中的各种创意。这正是这本书将要呈现的内容。DRY 是 Don’t Repeat Yourself 的首字母缩写,意思是不应该重复你已经做过的事。它是一种广为流传的编程理念,旨在提升代码某方面的可维护性:在改变某个参数时,做到只改尽量少的地方,最好是一处。强调 CSS 代码的 DRY 原则是一个贯穿本书的主题。DRY 的反面是 WET,它的意思是 We Enjoy Typing(我们喜欢敲键盘)或 Write Everything Twice(同样的代码写两次)。
1
2
3
4<div style="column-count: 3; background-color: seashell">
<h3 style="column-span: all; color: black">我们在现代 CSS 中所面临的挑战已经不在于如何绕过这些转瞬即逝的浏览器 bug。</h3>
<p style="color: black">如今的挑战是,在保证 DRY1①、可维护、灵活性、轻量级并且尽可能符合标准的前提下,把我们手中的这些 CSS 特性转化为网页中的各种创意。这正是这本书将要呈现的内容。DRY 是 Don’t Repeat Yourself 的首字母缩写,意思是不应该重复你已经做过的事。它是一种广为流传的编程理念,旨在提升代码某方面的可维护性:在改变某个参数时,做到只改尽量少的地方,最好是一处。强调 CSS 代码的 DRY 原则是一个贯穿本书的主题。DRY 的反面是 WET,它的意思是 We Enjoy Typing(我们喜欢敲键盘)或 Write Everything Twice(同样的代码写两次)。</p>
</div>
11.BFC渲染规则
-
BFC中元素垂直方向上的margin会重叠。
-
BFC是一个独立的元素,外面的元素不会影响到里面,里面的元素也不会影响到外面
-
BFC内元素不会与浮动元素发生重叠
-
计算BFC高度的时候浮动元素也会参与计算 【解决父元素高度塌陷问题】
12. BFC应用场景
-
清除浮动,防止父元素高度塌陷。
如果父元素没有设置高度,而子元素设设置了高度,正常情况下子元素会把父元素撑起来。
正常子元素会把父元素撑起来1
2
3<div style="width: 100%; border: 5px dotted palevioletred">
<div style="height: 32px; width: 100%; background-color: dodgerblue; text-align: center; line-height: 32px; color: white">正常子元素会把父元素撑起来</div>
</div>如果子元素设置了浮动,由于脱离了正常流的原因,父元素就不会得到它的高度,使父元素高度为0,俗称父元素高度塌陷。
子元素设置float后父元素高度塌陷1
2
3<div style="width: 100%; border: 5px dotted palevioletred">
<div style="float: left; height: 32px; width: 100%; background-color: dodgerblue; text-align: center; line-height: 32px; color: white">子元素设置float后父元素高度塌陷</div>
</div>这个时候我们只要在父元素上按照触发BFC的规则,得到一个BFC后,在BFC内部因为会计算浮动元素的高度,即可解决父元素高度塌陷的问题。
我们可以根据10. BFC触发条件里的条件创建BFC,当然大部分都会有副作用,比如把父元素也设置为浮动,或者把父元素绝对定位等等,都不太实用。常用的
overflow: hidden实际上也有副作用,你会看不到溢出的子元素。经过研究,我发现了两个没有副作用的方法。第一种是使用
display: flow-root。它被设计的目的大概就是为了创建BFC。父元素设置display: flow-root创建BFC1
2
3<div style="display: flow-root; width: 100%; border: 5px dotted palevioletred">
<div style="float: left; height: 32px; width: 100%; background-color: dodgerblue; text-align: center; line-height: 32px; color: white">父元素设置display: flow-root创建BFC</div>
</div>第二种是使用
column-span: all。这个属性的是在多原意是在多列容器中横跨所有的列。如果我们的项目里没有使用多列容器,我们给div上创建这个属性,也会创建一个BFC,而且由于我们没有使用多列容器,所以没有任何副作用。column-span: all 的元素将始终创建一个新的BFC,即使该元素没有包裹在一个多列元素之中。
父元素设置column-span: all创建BFC1
2
3<div style="column-span: all; width: 100%; border: 5px dotted palevioletred">
<div style="float: left; height: 32px; width: 100%; background-color: dodgerblue; text-align: center; line-height: 32px; color: white">父元素设置column-span: all创建BFC</div>
</div> -
避免外边距折叠
目前我的观点是这样的,如果两个元素,它们是上下分布的,那么就会产生外边距折叠。这包括BFC内部的元素,因为BFC只保证内部和外部之间互补干扰,至于内部之间的各种相互作用它就管不着了。所以我们可以看到下面的例子,外层div触发了BFC,但是内部的三个div之间的margin仍然被折叠了,按理说div1和div2之间的外边距应该等于 10 + 10 = 20px的,但是实际上只有10px。
1231
2
3
4
5<div style="display: flow-root; width: 100%; background-color: green">
<div style="margin: 10px 0; height: 32px; line-height: 32px; text-align: center; background-color: lightblue; color: black">1</div>
<div style="margin: 10px 0; height: 32px; line-height: 32px; text-align: center; background-color: lightblue; color: black">2</div>
<div style="margin: 10px 0; height: 32px; line-height: 32px; text-align: center; background-color: lightblue; color: black">3</div>
</div>但是我们可以很容易想到一个想法,我们把这些内部元素也用一个BFC包裹,这样它们之间就互不干扰了!外边距自然也就不会折叠了!
123我们在里层的div分别包裹在三个BFC中,可以看到它和div1与div3的外边距没有合并,总外边距变成了10 + 10 = 20px。
13. 画一个三角形
在这里我们先学习一下border的妙用。
1 | |
我平常使用border都是类似这样border: 5px solid red,它的结果就是盒子外面加一层5px的红色实心边框。但是实际上border四周的颜色是可以改变的,就比如上面的例子,利用border-color分别设置了上右下左的边框颜色,而且我们注意到一个特点,就是上下左右边框的划分。
它们首先是把盒子四周都扩大50px,这样就得到了一个更大的正方形。然后把大正方形和里面的content-box的四个顶点连起来,从而区分上下左右的边框。
那我们就想,如果把里面content-box缩小一点呢?
更小一点
如果里层的content-box的宽和高都是0呢?
令人兴奋的事情发生了,我们获得了四个三角形!它的出现原理和之前说的一样,都是两个矩形之间的顶点相连,只不过在content-box的宽和高都是零的情况下,大正方形的四个顶点将同时指向中心,最终实现了四个三角形的效果。
如果我们只想要四个三角中的一个,我们可以把其他三个颜色设置为透明transparant。
1 | |
有了制作三角形的技术,我们可以画一个可爱的对话框。
1 | |
只需要在div里绘制一个三角形就可以啦,这里选用了before伪元素,因为这种属于视觉层面的东西尽可能不要去影响dom,而应该使用CSS解决。
14. 画一个平行四边形
我们都知道平行四边形可以由一个矩阵变形而来,而CSS中transform中的skew函数可以实现类似变形的操作。
1 | |
现在我们来记忆一下正负的变形情况,因为skew的第一个参数表示沿横坐标扭曲元素的角度。
我目前是这样记忆的,当度数属于 [0deg, 90deg],矩形往左侧倾斜,度数的是 左侧的边与 垂直线之间的角度。
当度数属于 [-90deg, 0deg]的时候,矩形往右侧倾斜,度数的绝对值同样为 左侧的边与 垂直线之间的角度。
值得注意的是
transform: skew(-20deg, 0)可以由transform: skewX(-20deg)代替。
15. 画一个五角星
要画五角星,我们需要先来看看五角星的特点。

可以看到五角星内部实际上有一个正五边形。众所周知,五边形的内角和是540度。所以正五边形的每个角度是108度。由于五边形的每个角实际上都对应了一个等腰三角形,所以我们也可以求出来等腰三角形的两个等角是36度。
所以我们如果要画五角星,首先需要得到一个顶角为108度的等腰三角形。然后仔细思考一个,不同角度下的3个这种等腰三角形,就能得到一个五角星。
我们可能无法精确画出36度的等腰三角形,也许我们可以取一个近似值?记得么,3 4 5那个直角三角形的最小的角是36.8度,我们可以根据它来画出最基本的等腰三角形。
1 | |
这便是近似的36度的等腰三角形了。剩下的工作便是把它复制3份,然后旋转到相应得位置。
我们逆时针旋转36度,就得到了和之前图片里一样得粉色三角形。我们现在需要画出另外两个三角形。
1 | |
1 | |
由于度数是近似的,长度也是近似的,很难达到百分之一百精准。大致是一个三角形,如果我们把颜色换成同一个的话,看起来会更像。
目前我们已经用CSS画了三角形、平行四边形和五角星了,实际上这些图形都可以用
clip-path来绘制蒙版实现。以后看有时间画一下吧。这也是CSS面经的结尾了。
JavaScipt
1.JS原始数据类型有哪些?引用数据类型有哪些?
由于很多原始数据类型 有它的原始值包装类型,这里用小写表示原始值,大写表示包装类型。
JS中存在着7种原始值。资料来源MDN
- null
- undefined
- number
- string
- boolean
- symbol
- bigint
引用数据类型
- Object
- String
- Number
- Boolean
- Array
- Map
- Set
- Date
- RegExp
- Math
- Function
- 等等 【总之是对象就是引用数据类型】
2. 说出下面运行的结果,解释原因。
1 | |
结果是
p1: {name: 'fyq', age: 18}
p2: {name: 'hzj', age: 18}
函数传参的时候传递的是对地址的引用,函数中设置age会实际改变内存中的对象。所以p1发生了改变。然后右新建一个新的对象,作为函数的返回,p2变成了便是新对象的引用。
3. null是对象吗?为什么?
null不是对象,null是js中的一个原始值。typeof null会输出object是JS存在的一个悠久的bug。在JS的最初版本中使用的是32位系统,为了性能考虑使用低位存储变量的类型信息,000开头代表是对象,而null表示位全零,所以将它错误地判断为了object。
曾有一个 ECMAScript 的修复提案(通过选择性加入的方式),但被拒绝了。该提案会导致 typeof null === ‘null’。MDN
4. ‘1’.toString()为什么可以调用?
因为JS帮我们自动化做了许多工作。包括
- 创建一个String类型的实例
- 调用实例上的特定方法
- 销毁实例
可以把以上三部想象成执行了如下三行js代码。
1 | |
值得注意的是,自动创建的原始值包装对象只存在于 “1”.toString那一行代码,这意味着不能给原始值添加新的属性和方法。
1 | |
5. 0.1+0.2为什么不等于0.3?
因为JS中number类型是按照IEEE 754 来存储的,0.1在0.2在转换为二进制的时候会无限循环,由于标准位数的限制后面多余的位数会被裁掉,此时就出现了精度的损失,相加后的二进制在转化为十进制就会变成 0.30000000000000004
3后面有15个0
6. 什么是BigInt?
BigInt是JS中最新的基本数据类型。
由于JS中的number使用了IEEE 754标准,当整数大于 Number.MAX_SAFE_INTEGER(9007199254740991) 的时候,将会被自动四舍五入,所以会出现以下情况。
1 | |
这使得在JS中对大整数的算数运算有精度损失的风险,在BigInt出现之前,我们只能利用一些第三方库,比如bignumber.js。
而BigInt的出现打破了这个痛点。
要创建一个BigInt,我们可以直接在数字后面加上一个n即可,十分优雅,或者你也可以使用BigInt("9007199254740993")构造函数
1 | |
这里我还想讨论一个问题,那就是为什么构造一个bigint的时候,构造函数BigInt()之前没有new关键字。
根据我的想法,是因为这个BigInt() 不是一个包装函数的构造函数,它只是一个普通的转换函数。它的作用是把一个number原始值转化为一个bigint原始值。这和Number("1")这个转换函数是一样的,把字符串变成了number原始值。
解决了这个问题,我们可能还有一个疑问,我们知道了转换函数,那new BigInt()是不是会构造出bigint原始值的包装对象【primitive wrapper object】呢?很可惜,JS貌似没有提供这种方法。
1 | |
所以我们不能像new String("1"),new Number(1),new Boolean(true)这样创建原始值的包装对象了,但这样貌似没有什么不好的,要知道,在正常写代码中,几乎没有人会这样写,红宝书也是这样提醒我们的。
可以显式地使用 Boolean、Number 和 String 构造函数创建原始值包装对象。不过应该在确实必
要时再这么做,否则容易让开发者疑惑,分不清它们到底是原始值还是引用值。在原始值包装类型的实
例上调用 typeof 会返回"object",所有原始值包装对象都会转换为布尔值 true。
所以在没有人会显示声明原始值包装对象的考虑下,JS对新的数据类型,symbol和bigint都没有提供包装对象的构造函数。
但是实际上,我们还是可以用new Object(123n)来创建一个bigint的包装对象。
还可以参考一下这篇文章 为什么BigInt、Symbol被设计为无法new和extends的? 讲的也在理。
7. 为什么需要BigInt?
8. 如何创建并使用BigInt?
-
数字末尾加n
-
使用BigInt转型函数。
很多人,包括MDN 也说它是构造函数,但是鉴于它不能使用new关键字来创建包装对象的事实,我认为它更适合叫做转型函数,即把number原始值转换为bigint原始值。
简单使用如下。
1 | |
值得警惕的点
-
bigint不支持一元加号运算符,这可能是由于某些程序依赖+始终生成Number 或者抛出异常。更改+的行为也会破坏asm.js的代码。
1
2+"1" //1
+[] //0 -
因为隐式类型可能会丢失信息,所以不允许在bigint和number之间的混合操作。
1
1 + 1n //Uncaught TypeError: Cannot mix BigInt and other types, use explicit conversions -
不能将bigint传递web api或者js的内置函数,那些函数需要一个number类型的数字。
1
Math.max(1n, 2n) //Uncaught TypeError: Cannot convert a BigInt value to a number -
当boolean和bigint类型相遇时,bigint和number类似,即 只要不是 0n ,bigint都会当作 truthy
1
2
3
4
5
6if (0n) { //false
}
if (3n) { //true
} -
元素都为bigint的数组可以进行sort,但是sort默认是ascii排序,作用不大。
1
2
3
4let a = [2n, 11n, 3n]
a.sort() //[ 11n, 2n, 3n ]
a = [2n, 11n, 3n]
a.sort((a, b) => a - b) //Uncaught TypeError: Cannot convert a BigInt value to a number搞不太懂,为什么明明都是bigint,确报这个错,所以暂时没法用sort来真正的按值排序。
-
bigint可以正常地进行位运算 如 | & << >> ^
9.typeof 是否能正确判断类型?
对于原始类型来说,除了null都可以调用typeof显示正确的类型。
1 | |
对于引用数据类型,除了函数之外,都会显示"object"
1 | |
所以利用typeof来判断 引用数据类型 / 对象数据类型 是不合适的,更适合用instanceof。instanceof基于原型链查询,只要处于原型链中,判断永远为true。
1 | |
10. instanceof能否判断基本数据类型?
正常情况下不行,instanceof只适合用来判断 引用数据类型 / 对象数据类型,而不应该用来判断原始值。
如果强行重定义类内部的instanceof方法,那是可以的,但是本质上还是调用了typeof。
1 | |
这里的例子由于直接返回了typeof的判断,失去了原先instanceof的功能,如果我们在实际中,我们需要兼顾之前的返回值,应该在不破坏原先instanceof功能的情况下加入typeof的判断。
11. 能不能手动实现一下instanceof的功能?
核心: 基于原型链的向上查找
1 | |
实际上利用Object.prototype.isPrototypeOf()可以一句话判断。
1 | |
值得注意的是,必须要在某个类的prototype里调用这个函数,如果直接在类上调用是不行的。会全部返回false
1 | |
12. Object.is和===的区别?
Object在严格相等的基础上修复了一些特殊情况下的失误,具体来说就是 +0 与 -0,NaN 与 NaN。
1 | |
13. [] == ![]结果是什么?为什么?
根据MDN 当两操作数类型不同时会试图转化为同一个类型,具体规则如下。
-
当数字与字符串进行比较时,会尝试将字符串转换为数字值。
-
如果操作数之一是Boolean值,则将布尔操作数转化为0 / 1【false转0,true转1】
-
如果操作数之一是对象,另一个是数字或者字符串,会尝试调用对象的valueOf() 和 toString()方法将对象转化为原始值。
所以这里我们就可以知道[] == ![]的过程了。
-
[] == ![]首先判断两边,右侧有一个取非运算符,由于
[]对应的布尔值为true,则![]对应false。 -
[] == false对应之前说的第2种情况,即有一个操作数是布尔值,我们将布尔值转化为0。
-
[] == 0现在对应第3种情况,操作之一是对象,另一个是数字,则调用valueOf把对象转化为数字。
值得注意的是 [].valueOf() 的返回值貌似还是一个数组。但是Number([]) = 0
-
0 == 0true
14. JS中类型转换有哪几种?
-
转化为字符。
可以使用String()转型函数或者.toString()方法
1
2
3
4
5
6
7
8
9
10
11
12String(5) //'5'
5..toString() //'5'
String(false) //'false'
String(true) //'true'
String(Math.abs) //'function abs() { [native code] }'
String(Symbol.iterator) //'Symbol(Symbol.iterator)'
String([1, 2, 3]) //'1, 2, 3'
String({"wuuconix": "yyds"}) //'[object Object]'
String(new Map()) //'[object Map]'
String(123n) //'123'
String(null) //'null'
String(undefined) //'undefined' -
转化为数字。
可以使用Number()转型函数 / parseInt() / parseFloat()
1
2
3
4
5
6
7
8
9
10
11Number(1) //1
Number(true) //1
Number(false) //0
Number("1") //1
Number(null) //0
Number(undefined) //NaN
Number(Symbol.iterator) //Uncaught TypeError: Cannot convert a Symbol value to a number
Number([1, 2]) //NaN
Number({"wuuconix": "yyds"}) //NaN
Number(123n) //123
Number(Math.abs) //NaN -
转化为布尔值
可以使用Boolean()转型函数 还可以使用!!转型
1
2
3
4
5
6
7
8
9
10Boolean(0) //false
Boolean(-0) //false
Boolean(NaN) //false
Boolean("") //false
Boolean(null) //false
Boolean(undefined) //false
Boolean([]) //true
Boolean({}) //true
Boolean(Symbol.iterator) //true
Boolean(0n) //false
15. == 和 ===有什么区别?
全等运算符 === 与相等运算符 == 最显著的区别是,如果操作数的类型不同,== 运算符会在比较之前尝试将它们转换为相同的类型。
而全等运算符 === 如果两个操作数的类型不同将直接返回false,不会进行类型转化。
== 在两个操作数类型不同时的转化规则如下。
如果两个操作数是不同类型的,就会尝试在比较之前将它们转换为相同类型:
-
当数字与字符串进行比较时,会尝试将字符串转换为数字值。
-
如果操作数之一是Boolean,则将布尔操作数转换为1或0。
-
如果操作数之一是对象,另一个是数字或字符串,会尝试使用对象的valueOf()和toString()方法将对象转换为原始值。
1 | |
16. 对象转原始类型是根据什么流程运行的?
-
如果有Symbol.toPrimitive() 对象,优先调用返回
-
调用valueOf() 如果转化为原始类型,则返回
-
调用toString() 如果转化为原始类型,则返回
-
如果都没有返回原始类型,会报错
1 | |
17. 如何让if(a == 1 && a == 2)条件成立?
首先把a定义为一个对象,当一个对象和一个数字相比较的时候,会调用内部的valueOf方法,我们需要改变这个方法,让每次调用后的值 加 1
1 | |
18. 什么是闭包?
一个函数对其周围状态(词法环境 lexical environment)的引用捆绑在一起,这样的组合就是闭包 closure。闭包可以让你在一个内层函数种访问到其外层函数的作用域。在JavaScript中,每创建一个函数,闭包就会在函数创建的同时被创建出来。
19. 闭包产生的原因?
闭包产生的本质就是,当前环境中存在指向父级作用域的引用。
1 | |
这里f2引用了父作用域中的a变量,f2和a的组合就是一个闭包。我们可以看到f1把f2以返回值的返回了。但是反不返回函数这不是闭包的本质特点,f2和a的组合就是闭包,而不用管是否将f2返回。我们返回的目的是在外部使用这个闭包。
实际上利用全局变量的方式也可以实现使用闭包。
1 | |
20. 闭包有哪些表现形式?
在真实的场景中,究竟在哪些地方能体现闭包的存在?
-
返回一个函数。见19. 闭包产生的原因?
-
作为函数参数传递
1
2
3
4
5
6
7
8
9
10
11
12
13
14let a = 1
function foo() {
let a = 2
function baz() {
console.log(a)
}
bar(baz);
}
function bar(fn) {
fn();
}
foo(); -
在定时器、事件监听、Ajax请求、跨窗口通信、Web Workers或者任何异步中,只要使用了回调函
数,实际上就是在使用闭包。 -
IIFE
Immediate Invoked Function Expression立即执行函数表达式也算创建闭包,因为它保存了全局作用域和当前的函数作用域,可以使用全局的变量实际上是个函数就能使用全局作用域,所以我认为每个函数都是闭包的表现形式。
21. 如何解决下面的循环输出问题?
1 | |
会全部输出6。由于JS单线程eventLoop机制,每次调用setTimeout函数都会把这个任务加入消息队列,而且不会立刻执行,而是等主线程的for循环结束后才开始执行。由于执行输出i的时候会顺着作用域链到达全局作用域,而这时因为i已经变成6退出了循环,所以之后所有的回调都会输出6。
解决方法:
-
使用let
-
使用IIFE
1
2
3
4
5
6
7for (var i = 1;i <= 5;i++){
(function(j){
setTimeout(function timer(){
console.log(j)
}, 0)
})(i)
} -
给定时器传入第三个参数, 作为timer函数的第一个函数参数
1
2
3
4
5for (var i = 1;i <= 5; i++){
setTimeout(function timer(j){
console.log(j)
}, 0, i)
}setTimeout的第一个一般都是一个函数,第二个参数是延时,第三个参数即以后如果有的话,就是传给第一个函数的参数们。
2和3的解决思路都是一致的,不用i,而在循环的过程中把i的值赋给一个变量传递给计时器,让回调时用这个变量。
22. 原型对象和构造函数有何关系?
在JavaScript中,每当定义一个函数数据类型(普通函数、类)时候,都会天生自带一个prototype属性,
这个属性指向函数的原型对象。
当函数被new调用,这个函数就成为了构造函数,返回一个全新的实例对象,这个实例对象有一个__proto__属性,指向构造函数的原型对象。
graph LR
1([实例对象])
2{构造函数}
3(原型对象)
1--"__proto__属性"-->3
2--"new"-->1
2--"prototype属性"-->3
23. 能不能描述一下原型链?
JS中的一个实例对象可以通过__proto__指向自己的原型对象。然后这个原型对象还可以继续通过__proto__来访问到父级的原型对象,直到访问到Object的原型对象,然后Obejct原型对象的__proto__就指向null了。
graph LR
1([实例对象])
2{构造函数}
3(原型对象)
4(父级原型对象)
5(Object.prototype)
6(null)
1--"__proto__属性"-->3
2--"new"-->1
2--"prototype属性"-->3
3--"__proto__属性"-->4
4--"..."-->5
5--"__proto__属性"-->6
- 对象的
hasOwnProperty()来检查对象自身是否含有某个属性 - 使用in检查对象是否有某个属性,如果对象中没有,但是原型链中有,也会返回true
24. JS如何实现继承?
以下分类基于红宝书
-
借助原型链继承
它的核心特征是把子类的原型设置为父类的一个实例。这样能够同时或者父类的实例方法与原型方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19function SuperType() {
this.name = "super"
this.lan = ["html", "css", "js"]
}
SuperType.prototype.sayHi = function sayHi() {
console.log(`Hi, I'm ${this.name}`)
}
function SubType() {
this.name = "sub"
}
SubType.prototype = new SuperType() //核心特征
let instance1 = new SubType()
let instance2 = new SubType()
instance1.sayHi() //Hi, I'm sub 可以使用父类原型上的方法
instance1.lan.push("vue")
console.log(instance2.lan) //[ 'html', 'css', 'js', 'vue' ]它看起来非常好,能够顺畅地得到父类地所有属性和方法,但是实际上有问题。
由于子类地原型是父类地一个实例,所以父类地实例属性变成了子类地原型属性。所以子类的实例会共享这些属性,一个子类实例去改变了原型属性后,其他的子类也会收到影响。
此外,它还有一个问题是无法给子类的构造参数传参,或者说根据子类的实例个性化的传参,因为子类调用父类构造函数的时候就是
SubType.prototype = new SuperType()这一处,而这里是对于整个子类而言的一次性操作,无法根据每个子类实例特定化地向父类构造函数传参。 -
盗用构造函数
其核心特征就是在子类地构造函数中利用
call来调用父类的构造函数,从而简化代码,让子类也有这些属性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function SuperType(name) {
this.name = name ?? "super"
this.lan = ["html", "css", "js"]
}
SuperType.prototype.sayHi = function sayHi() {
console.log(`Hi, I'm ${this.name}`)
}
function SubType(name) {
SuperType.call(this, name) //核心特征
}
let instance1 = new SubType("instance1")
let instance2 = new SubType("instance2")
instance1.lan.push("vue")
console.log(instance2.lan) //[ 'html', 'css', 'js' ]
instance1.sayHi() //TypeError: instance1.sayHi is not a function盗用构造函数和借助原型链正好相反,因为属性不是定义在原型上的,而是实例属性,所以实例之间可以互不影响。而且它还可以根据对不同的子类实例在调用父类构造函数的时候进行个性化的传参。
但是由于全程没有用到原型,所以子类将无法使用父类原型上的方法。
-
组合继承
由于
原型链和盗用构造函数如此互补,我们便可以把两者优点结合起来,形成 组合继承。它的特征是利用 原型链来继承父类原型上的方法,利用盗用构造函数的方法来继承父类的实例属性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19function SuperType(name) {
this.name = name ?? "super"
this.lan = ["html", "css", "js"]
}
SuperType.prototype.sayHi = function sayHi() {
console.log(`Hi, I'm ${this.name}`)
}
function SubType(name) {
SuperType.call(this, name) //盗用构造函数继承父类实例属性
}
SubType.prototype = new SuperType() //借助原型链继承父类原型上的方法
let instance1 = new SubType("instance1")
let instance2 = new SubType("instance2")
instance1.lan.push("vue")
console.log(instance2.lan) //[ 'html', 'css', 'js' ]
instance1.sayHi() //Hi, I'm instance1看起来组合继承似乎已经很完美了,即继承了实例属性也继承了原型上的方法。
但是有一点不太完美,那就是它调用了两次父类构造函数,第一次是设置子类原型的时候,第二次是子类构造函数中call调用。
有些资料说这调用两次影响性能,而我认为更应该思考的是,它调用两次后的造成的结果。
第一次调用,把父类的的一个实例设置为了子类的原型,这会发生什么?子类的原型上会出现这些属性。
而第二次调用,子类的构造函数中调用了父类构造对象,结果是子类也拥有了这些实例对象,所以由于遮蔽效应,我们访问子类实例
name的时候,会先访问子类的实例属性name,而不会去访问原型上的name,这一点消除了使用单独使用原型链继承的缺点。但是既有实例属性,原型上又有,虽然没什么影响,但是总感觉不太好,在之后的
寄生式组合继承中我们可以解决这个问题。 -
原型式继承。
DC在2006提出的,它的核心是一个函数。
1
2
3
4
5function object(o) {
function F() {} //创建临时构造函数
F.prototype = o //设置o为临时构造函数的原型
return new F() //返回临时构造函数生成的实例
}在ES5中,实现了
Object.create()函数,规范化了原型式继承。下面的代码里我将直接使用这个函数。原型式继承的特征:没有构造函数,把父对象设置为子对象的原型
1
2
3
4
5
6
7
8let SuperObject = { //不是构造函数,而是一个对象
name: "super",
lan: ["html", "css", "js"]
}
let instance1 = Object.create(SuperObject)
let instance2 = Object.create(SuperObject)
instance1.lan.push("vue")
console.log(instance2.lan) //[ 'html', 'css', 'js', 'vue' ]由于子对象的原型是父对象,所以同样会和
借助原型链继承方法出现类似的缺点,即各个实例之间更改属性后会相互影响,因为实际上更改的都是原型上的属性。 -
寄生式继承
寄生式继承我认为和原型式继承一模一样,只不过它可能更加强调【以某种方式增强对象】
它同样需要基于
Object.create() -
寄生式组合继承
最完美的继承方式。我们可以从它的名字中大概能猜出了它的构成了。
首先它是组合继承,借助原型链+盗用构造函数,然后它还是寄生式的,会用到
Object.create。我们之前提高组合继承很完美,但是子类的原型因为是一个父类的实例,所以原型上会有一些属性,虽然由于子类还有同名实例属性的原因,这些原型上的属性会被遮蔽,但是总感觉不太好。所以我们可以利用寄生式来解决这个问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20function SuperType(name) {
this.name = name ?? "super"
this.lan = ["html", "css", "js"]
}
SuperType.prototype.sayHi = function sayHi() {
console.log(`Hi, I'm ${this.name}`)
}
function SubType(name) {
SuperType.call(this, name) //盗用构造函数继承父类实例属性
}
SubType.prototype = Object.create(SuperType.prototype) //寄生
SubType.prototype.constructor = SubType //寄生增强
let instance1 = new SubType("instance1")
let instance2 = new SubType("instance2")
instance1.lan.push("vue")
console.log(instance2.lan) //[ 'html', 'css', 'js' ]
instance1.sayHi() //Hi, I'm instance1我们把之前的
SubType.prototype = new SuperType()换成了中间两行寄生特点的代码。这会产生什么影响?由于子类的原型不再是父类的实例,而直接是父类的原型对象的拷贝。所以子类的原型上将不会出现父类的实例对象,解决了组合继承的不完美之处。
此外还通过重新指向子类原型的
constructor为子类的构造函数,使得逻辑更加清楚。这一句就体现出了寄生继承的特点:增强
不光是简单的拷贝了一份父类的原型对象,而且设置了新的constructor指针,增强了这个拷贝的对象。
25. 函数的arguments为什么不是数组?如何转化成数组?
它无法调用数组的方法,说明它的原型不是数组的原型,可以证明他不是数组。由于它的属性从0开始排,可以算作类数组。
常见的类数组还有HTMLCollection和NodeList。
转化为数组的方法。
-
Array.prototype.slice.call(arguments)
-
Array.from(arguments)
-
ES6展开运算符 […arguments]
-
Array.prototype.concat.apply([], arguments)
26. forEach中return有效果吗?如何中断forEach循环?
没有效果。可以通过把整个forEach放在try-catch结构里面。当符合某个条件后进行退出。
1 | |
27. JS判断数组中是否包含某个值
1 | |
-
Array.prototype.indexOf
如果数组中有给定的数,则返回它第一个下标,否则返回-1
-
Array.prototype.includes
判断数组中是否有某个数,有则返回true
-
Array.prototype.find
返回第一个符合条件的元素的值
-
Array.prototype.findIndex
返回第一个符合条件的元素的下标
28. JS中flat—数组扁平化
假设我们现在需要处理这个多维数组。
1 | |
-
利用ES6的flat
1
array.flat(Infinity) //[ 1, 2, 3, 4, 5, 6 ] -
replace + split
1
str.replace(/(\[|\])/g, "").split(",").map(x => Number(x)) //[ 1, 2, 3, 4, 5, 6 ]思路:先把数组变成字符,然后把字符里的方括号全部用正则去掉。然后根据逗号分割为数组,由于分割后的元素都变成了字符串,所以用map来转数字。
-
replace + JSON.parse
1
JSON.parse("[" + str.replace(/(\[|\])/g, "") + "]")和第二个方法类似,都是用正则把方括号全部去掉,它们的区别是字符串转数组的方法。
-
手动递归
1
2
3
4
5
6
7
8
9
10
11
12
13let array = [1, [2, [3, [4, 5]]], 6]
let result = []
let dfs = (array) => {
for (let i = 0; i < array.length; i++) {
if (Array.isArray(array[i])) {
dfs(array[i])
} else {
result.push(array[i])
}
}
}
dfs(array)
console.log(result) //[ 1, 2, 3, 4, 5, 6 ] -
利用reduce实现递归
1
2
3
4
5
6
7let array = [1, [2, [3, [4, 5]]], 6]
let dfs = (array) => {
return array.reduce((prev, cur) => {
return prev.concat(Array.isArray(cur) ? dfs(cur) : cur)
}, [])
}
console.log(dfs(array)) -
扩展运算符
1
2
3
4let array = [1, [2, [3, [4, 5]]], 6]
while (array.some(item => Array.isArray(item))) {
array = [].concat(...array) //每循环一次就会让多维数组降一维
}
29. 什么是高阶函数
高阶函数是一个接受函数作为参数或者将函数作为返回值的函数。
比如Array.prototype.map,Array.prototype.filter,Array.prototype.reduce是语言内置的一些高阶函数。
1 | |
可以看到reduce接受的第一个参数是一个函数,所以它是一个高阶函数
30. 数组中的高阶函数
-
map
1
2
3
4//语法
let new_array = arr.map(function callback(currentValue[, index[, array]]) {
// Return element for new_array
}[, thisArg])第一个参数是一个回调函数,回调函数的支持三个参数,分别是 数组中当前正在处理的值、正在处理的值的小标、和方法调用的数组。
第二个参数可以传入一个对象,然后就可以在回调参数里调用
this.property了。实际上map的回调参数只需要一个函数即可,可以不必显示调用它。
比如我们常见的把数组里的字符全部转化为数组的情况,可以直接这样写。
1
2let array = ["1", "2", "3"]
array = array.map(Number) //[ 1, 2, 3 ]因为Number是一个转型函数,所以直接传递它即可。
-
reduce
第一个参数为回调函数,回调函数的第一个参数
previousValue表示上一个调用回调的返回值。第二个参数currentValue代表当前正在处理的值,第三个currentIndex代表数组正在处理的值的下标,第四个array表示正在处理的数组。第二个参数
initValue可选,表示第一次调用回调时的previousValue的值。如果没有设置,则会将previousValue设置为数组的第一个元素,然后currentValue设置为数组的第二个元素。 -
filter
1
2//语法
var newArray = arr.filter(callback(element[, index[, array]])[, thisArg])第一个参数为回调函数,第一个参数表示当前处理的值,第二个下标,第三个数组。
第二个参数可选,用于当作
this的值。1
2let array = [1, [1], [2]]
array = array.filter(Array.isArray) //[ [ 1 ], [ 2 ] ] -
sort
传递一个排序函数。
1
2let a = [2, 1, 4, 3]
a.sort((a, b) => a - b) //[ 1, 2, 3, 4 ]值得注意的是,sort和前面3个不通,前面3个高阶函数对原函数没有影响,map和sort都会生成一个新的函数,reduce一般得到的是一个值,而sort由于采用了原地算法,所以会影响到原函数。
40. 谈谈你对JS中this的理解
以下内容出自 《你不知道的JavaScript(上卷)》
每个函数的this是在被调用时确定的,完全取决于函数的调用位置。
this的绑定规则可以分为四条。
-
默认绑定
1
2
3
4function f() {
console.log(this) //Window {0: global, window: Window, se...}
}
f()1
2
3
4
5"use strict"
function f() {
console.log(this) //undefined
}
f()在非严格模式下,将把this绑定到全局对象,在浏览器器里就是Window对象。在严格模式下,就会返回this就会绑定到undefined
-
隐式绑定
它的特点实际上就是通过类似
obj.f()的形式来调用函数,这个时候它的this就会被隐式绑定到obj这个对象。1
2
3
4
5
6
7
8
9
10function f() {
console.log(this) // {description: "I'm an object", f: ƒ}
}
let obj = {
description: "I'm an object",
f
}
obj.f() -
显示绑定
它利用的就是我们常见的
call, apply, bind等函数,它们会把this显示绑定到某个对象值。其中bind会生成一个新的函数,方便后续使用。
1
2
3
4
5
6
7
8
9
10
11
12
13function f() {
console.log(this)
}
let obj = {
description: "I'm an object"
}
f.call(obj) //{description: "I'm an object"}
f.apply(obj) //{description: "I'm an object"}
f() //Window {0: global, window: Window, self:...}
let newF = f.bind(obj)
newF() //{description: "I'm an object"} -
new绑定
利用new来调用构造函数的时候,JS会新创建一个对象,并且会把函数中的this绑定为这个新对象。
1
2
3
4
5
6
7
8
9function f(name) {
this.name = name
this.echo = function echo() {
console.log(this)
}
}
let instance = new f("instance")
instance.echo() //f { name: 'instance', echo: [Function: echo] }
43. 数据是如何存储的?
基本数据类型保存在栈中,引用数据类型保存在堆中。
有一种特殊情况,如果是闭包中的基本数据类型,它也会保存在堆中。
对应赋值操作,原型数据类型的数据直接完整地复制变量值,对象数据类型的值则是复制引用地址。
为什么不全部用栈来保存数据呢?因为栈除了有保存变量的功能外,它还有创建并切换函数上下文的功能,如果用栈来保存复杂的数据,那么切换上下文的开销会变得很大。
45. 描述一下 V8 执行一段JS代码的过程?
-
解释器对源码进行词法分析和语法分析来生成抽象语法树
AST -
解释器利用AST生成字节码
字节码是介于AST 和 机器码之间的一种代码,但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码然后执行。
字节码仍然需要转化为机器码,但是我们可以不用一次性将所有得字节码转化为机器码,而是通过解释器逐行执行字节码,省去生成二进制文件的操作,大大降低了内存的压力。
-
由解释器逐行执行字节码,在遇到热点代码
Hot Spot Code时启动编译器进行编译,生成对应机器码,以优化执行效率。字节码有两种被执行的方式,一种是通过解释器逐行解释,但是如果遇到循环的代码,解释器就要重复地去解释,浪费了很多地时间,所以JS不光可以解释字节码,还会在遇到热点代码时,调用编译器进行编译得到机器码,在之后再次遇到直接运行机器码,极大提升执行效率。
这种字节码根编译器和解释器结果的技术被叫做 即时编译
just-in-time compilation JIT
46. 宏任务(MacroTask)引入
JS中所有的任务分为同步任务和异步任务。而异步任务可以分为宏任务和微任务。
宏任务包括,setTimeout, setInterval, DOM事件等,它的特点是在是两个宏任务之间会对页面进行重新渲染,使得宏任务能够和DOM任务进行有序的执行。
47. 微任务(MicroTask)引入
在宏任务内部会有一个微任务队列,当一个宏任务完成之后,如果它内部的微任务队列为空,它就会开始运行下一个宏任务,如果不为空,它就会将依次完成所有微任务,执行好后再去执行下一个宏任务。常见的微任务有MutationObserver, Promise, 等,V8的垃圾回收机制也是微任务。
值得注意的是Promise里并非全部都是微任务,只是.then, .catch等回调函数才是异步的。
48. 理解EventLoop:浏览器
EventLoop 就是在不断循环中处理宏任务与微任务的一个循环。
我们需要了解循环过程中,同步任务、宏任务和微任务的执行先后顺序,以下面这个代码为例。
1 | |
我们现在来进行解释。
-
首先将整段脚本作为第一个宏任务执行。
-
执行过程中将同步代码直接执行,宏任务进入宏任务队列,微任务进入微任务队列。
console.log(“script start”) 是同步代码,直接执行,作为第一个输出,setTimeout是一个宏任务,加入宏任务队列。Promise的处理器函数(就是当作参数的哪个函数)中实际上也是同步代码,所以第二个和第三个输出的是promise1和promise2。Promise.then() 是一个微任务,会被加入微任务队列。最后那个console.log(“script end”) 也是一个同步代码,会被直接执行。
-
当前宏任务执行完出队,检查微任务队列,如果有则直接执行,直到微任务队列为空。
现在微任务队列有一个Promise.then的微任务,我们将它运行完毕,输出 promise then。
-
执行浏览器UI线程的渲染工作
-
检查是否有Web Worker任务,有则工作
-
执行队首新的宏任务,回到2,依次循环,直到宏任务和微任务队列都为空。
新的宏任务从宏任务队列中拿出来,现在只有一个宏任务了,即setTimeout。运行完毕后,宏任务和微任务队列都空了。
50. nodejs 和 浏览器关于eventLoop的主要区别
两者对主要的差别在于浏览器中的微任务是每个相应的宏任务执行的。而Node.js中微任务是在不同的阶段之间执行的。
浏览器中的微任务为什么说是在相应的宏任务中执行的呢?因为微任务首先需要被加入到微任务队列,而加入的这个过程肯定发生在某个宏任务的过程中。所以微任务的执行就会发生在那个宏任务的末尾。
Vue
1.什么是MVVM ?
它是Model-View-ViewModel的缩写,它是一种设计思想。
-
其中Model层代表数据模型,也可以在其中定义一些数据修改和操作的业务逻辑
-
View层代表UI,负责将数据模型转化为UI展现出来。
-
ViewModel则负责同步View和Model。
-
在MVVM中,View和Model没有直接的联系,而是通过ViewModel进行双向交互,从而实现View的变化会同步到Model上,Model的变化也会立即反映到View上。
-
ViewModel通过双向数据绑定把View和Model连接了起来,而View和Model之间的同步工作完全是自动的,无需人为干涉,开发者只需关注业务逻辑而不用手动操作DOM。
2.mvvm和mvc区别?它和其它框架(jquery)的区别是什么?哪些场景适合?
MVC是Model-View-Controller的缩写。它和MVVM都是设计思想,MVVM实际上是MVC的改进版,即把Controller改进为了View-Model。
MVC中大量的DOM操作会影响页面的渲染性能,加载速度慢,影响用户体验,而ViewModel则避免了这种大量的DOM操作。
它和Jquery的区别是 mvvm不需要用户手动进行dom操作,mvvm实现了数据和视图的双向绑定,而且同步过程是完全自动的。
MVVM非常适合数据操作很多的场景。
优秀的参考链接:前端面试 vue 部分 (1)——谈谈你对 MVVM 的理解
3. 组件之间的传值?
父组件向子组件传值:
-
父组件在调用子组件时直接在子组件的标签里写属性。
1
<child :custom_attribute="something"></child> -
子组件写
props属性表明哪些属性是从父组件传递过来的,然后在html模板里直接用即可。1
2
3
4
5
6
7
8<template>
<p> {{ custom_attribute}} </p>
</template>
<script>
export default {
props: ["custom_attribute"] //从父组件哪里得到的
}
</script>
子组件向父组件传值:
-
子组件设置
emits属性表示会向父组件传递哪些事件,然后在合适的地方调用事件。1
2
3
4
5
6
7
8<template>
<button @click="$emit('custom_event', 'some_value')">
</template>
<script>
export default {
emits: ['custom_event']
}
</script>值得注意的是
$emit第一个参数代表自定义事件的名称,父组件可以通过v-on:来监听这个你自定义的事件,就像它是原生JS事件一样,然后$emit的第二个,第三个甚至更多的参数将可以用来给你这个自定义的事件传递参数。从而实现传值的目的。 -
父组件在子组件的标签上监听事件。
1
<child @custom_event="handle_custom_event"></child>值得注意的是custom_evnet的所有参数将会依次传给handle_custom_event函数。
我写了一个小页面,父组件就是App.vue,子组件里面就是一个img,然后父组件里有一个input输入框和一个回显框,在父组件里输入图片的url,这个url将通过props的方式传递给子组件,然后子组件将之设置为图片的src,然后子组件的图片在加载完毕或者加载失败后向父组件传递以后个自定义事件echo 让父组件在回显框里输出一些回显。
在线链接:https://wuuconix.github.io/static/vue-parent-child/
页面源码:https://github.com/wuuconix/static/tree/main/vue-parent-child/src
4.Vue 双向绑定原理
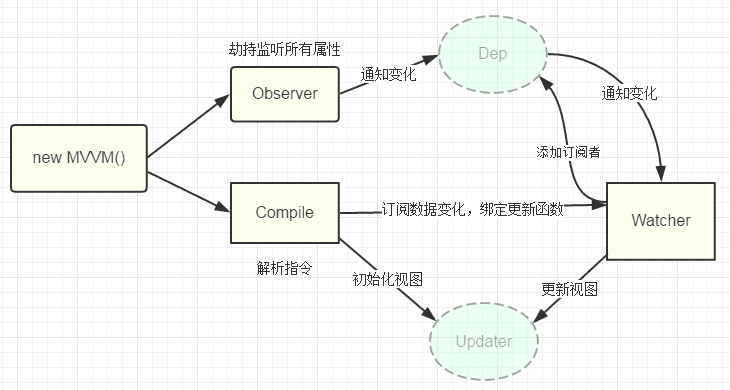
Vue双向绑定的主要原理可以概括为数据劫持 + 发布者-订阅者 的方法。
Vue的双向绑定主要依靠三大部件,Observer, Complie和Watcher。
Observer负责通过Object.defineProperty对属性进行劫持,设置相应属性的setter和getter。当相应数据发生变化后,会调用Dep.notify()通知数据的变化。
Complie负责对模板进行解析,包括模板指令和模板中的值,从而初始化视图,并且通过Watcher订阅数据变化,绑定更新函数。
Watcher则充当Observer和Complie之间的桥梁。当Observer发现属性被set或者get的时候,会调用Dep.notify()发起通知,Dep会调用所有订阅它的Watcher里的update方法,执行Complie绑定的回调函数,实现更新视图。
而MVVM作为数据绑定的入口,整合了Observer, Complie和Watcher三大部件。
5. 描述下 vue 从初始化页面–修改数据–刷新页面 UI 的过程?
初始化页面:首先Observer遍历所有属性,利用Object.defineProperty来劫持属性,设置相应的getter和setter。然后Complier负责解析模板指令,替换为数据,然后初始化视图,Complier会订阅一个Watcher来更新视图,此时Watcher会将自己添加到消息订阅器中,此时初始化完毕。
修改数据:当数据被修改时,会被Observer监听到,Oberser会调用Dep.notify() 来通知数据的变化,这是Dep会遍历它所有的订阅者,调用其update函数,Vue会根据内部的diff算法,patch相应的更新完成对视图的改变。
6. 你是如何理解 Vue 的响应式系统的?
-
每个Vue组件都会有一个与之对应的Watcher实例。
-
Vue的data上的属性会被设置setter和getter。
-
当Vue component render函数被调用的时候,data会被touch,即被读,getter函数会被调用,此时vue会去记录此Vue component所依赖的所有data【这一个过程被叫做依赖收集】
我的理解是形成了Dep对象。
-
data被改用时,setter方法会被调用,此时vue会通知所有依赖此data的组件去调用它们的render函数进行更新。
7. 虚拟 DOM 实现原理
-
虚拟DOM是一种JavaScript对象,它是对真实DOM的抽象。
-
状态变更时,会调用Diff算法记录新数和旧树的差别。
-
最后把差异更新到真正的DOM
由于Diff算法的存在,会在最小限度内实现状态更新,最终的DOM操作可能会很少,比直接操作DOM的效率高上很多。
8. Vue 中 key 值的作用?
Vue中key的一种常见用法是在v-for中为每个虚拟节点设置一个标识,从而在虚拟DOM算法中起到提示的作用,可以提高虚拟DOM算法的效率。
还有一种使用场景是在你需要 不复用某个元素或者组件的时候,为组件设置一个key可以让它强制是一个新的元素或者组件。
9. Vue 的生命周期
Vue的声明周期主要分为八个阶段。
-
beforeCreate
vue实例的挂载元素el和数据对象data均为undefined
-
created
data已经初始化完成,el仍未被挂载。
-
beforeMount
-
mounted
el挂载完成
-
beforeUpdate
-
updated
-
beforeUnmount
-
unmounted
在第一次页面加载时会触发前4个钩子。
DOM渲染在mounted中完成。
这里我又写了一个小页面,它会在各个声明周期输入 this.$data.src 和 this.$el。方便我们查看各个声明周期中data和el的情况。
在线链接:https://wuuconix.github.io/static/lifecycle/
页面源码:https://github.com/wuuconix/static/tree/main/lifecycle/src
以下是该页面在不同生命周期下的输出。
1 | |
可以看到,在beforeCreate的时候,data作为一个对象已经存在了,但是我们定义的那些变量还没有形成,所以访问 this.$data.src 返回了undefined。
在beforeMount 包括之前,el一直是null,表示vye实例还没有挂载到某个DOM上。
值得注意的是 beforeUpdate 的时候,data实际上已经发生变化了,所以beforeUpdate和updated输出的src都是同一个,即新的src。
beforeUnmount和unmounted的测试结果令我吃惊,貌似在卸载后仍能得到data,并且这个vue实例貌似还能访问到el。
10. Vue 组件间通信有哪些方式?
-
prop/$emit
这个适合父子之间传递值。之前写过,参考3. 组件之间的传值?
-
eventBus 事件总线
事件总线非常适合跨度非常大的祖先-后辈组件或者两个兄弟组件。它通过全局api来实现数据传递。
vue2中主要借助全局api $emit 和 $on。 而在vue3中把eventBus取缔了,如果还想使用类似的用法,可以使用mitt库。
我写的小页面,利用了mitt库实现了事件总线的操作。
在线链接:https://wuuconix.github.io/static/eventBus/
页面源码:https://github.com/wuuconix/static/tree/main/eventBus/src
-
listeners
vue3中已经取消了attrs中也可以传递事件方法了。
这种方法也只适合父子组件之间的传值。因为attrs 还可以包含事件,而普通的props操作貌似只能传递属性,$attrs的作用更大些。
在线链接:https://wuuconix.github.io/static/$attrs/
页面源码:https://github.com/wuuconix/static/tree/main/$attrs/src
-
provide/inject
这种方法非常好,适合跨代的祖先-后代组件,但是不适用于兄弟组件
它的使用方法是在一个组件组件里provide一个变量,然后在某个后代组件后inject后,这个变量就会变成后代组件的一个属性可以使用了。
在线链接:https://wuuconix.github.io/static/provide-inject/
页面源码:https://github.com/wuuconix/static/tree/main/provide-inject/src
-
children 与 ref
vue3中已经将parent api方法还在。
这种方法非常适合父子组件。父组件在调用子组件的标签那里设置一个ref,然后就可以通过
this.$refs.child.来访问到子组件的所有属性和方法了。子组件则可以通过
this.$parent.来访问到父组件中所有的属性和方法。可以说是父子组件传值的首选方法,因为它直观又简单。
在线链接:https://wuuconix.github.io/static/refs-parent/
页面源码:https://github.com/wuuconix/static/tree/main/refs-parent/src
-
vuex
vuex是vue官方出的用来解决大型网页应用中组件之间传值的插件。
它的功能是将某些组件之间需要公用的属性放在一个store里面,实现方便的公用,并且能够保证响应式。父组件把这个store里面的属性改变了,子组件的页面会进行刷新。
而且由于它和eventBus,api是全局的,我们可以在 任何组件,包括跨代的祖先-后代组件和兄弟组件中都可以方便的使用。
它唯一的缺点是它需要npm安装包,对于小型网页来说可能有些小题大做了。
11. vue 中怎么重置 data?
利用this.$options.data(this)可以得到原始的data数据。
然后我们可能会想直接 this.$data = this.$options.data(this) 来充值data,但是这样实测是不行的,可能由于直接把$data换成另外一个对象后,模板里面的数据可能还是绑定的之前的data,所以页面不会发生变化。好在我们可以用Object.assign把原本的data的值覆盖掉现在data的值。由于data整个对象没有变化,只是里面的值发生了变化,所以可以实现页面响应的效果。
1 | |
同样我写了一个小页面来学习并实践。
在线链接:https://wuuconix.github.io/static/data-reset/
页面源码:https://github.com/wuuconix/static/tree/main/data-reset/src
12. 组件中写 name 选项有什么作用?
-
项目使用keep-alive时,可以搭配组件name进行缓存过滤
-
递归调用组件需要通过name来调用自身
-
name的值会在vue-devtools中展示出来,如果不设置的话,默认是vue文件的名字。
在不使用cli方式的情况下,没有单个vue组件了,vue-devtools中看到的可能就是
<AnonymousComponent>了
13. vue-router 有哪些钩子函数?
全局的守卫有3个,路由规则独享的守卫有1个,组件内的守卫有3个
-
全局前置守卫 this.$router.beforeEach
-
全局解释守卫 this.$router.beforeResolve
-
全局后置守卫 this.$router.afterEach
-
路由独享的守卫 beforeEnter
-
组件内的守卫 beforeRouteEnter beforeRouterUpdate beforeRouteLeave
写了一个有趣的页面用来学习各种路由守卫。
在线链接:https://wuuconix.github.io/static/vue-router/
页面源码:https://github.com/wuuconix/static/tree/main/vue-router/src
14. route 和 router 的区别是什么?
this.$router 就是全局路由实例对象,我们之前说的钩子函数中的,beforeEach, beforeResolve, afterEach都是它的方法。
而this.$route 就是一个路由信息对象,和我们那些守卫中的 to, from 的对象是同一种对象,只不过我们可以直接调用this.$route来得到当前的路由信息。
路由信息对象中包括 fullPath path query hash 等属性。
1 | |
17. Vuex 有哪几种属性?
有五种,分别是 State Getter Mutation Action Module
20. v-show和v-if指令的共同点和不同点
-
v-show是通过css的display:none 让其显示或者隐藏
-
v-if 是通过直接销毁和重建DOM达到元素隐藏和显示的效果。
HTTP
22. HTTP/2 有哪些改进?
首先我们来看以下http/1.1 和 http/2的区别吧。
这个速度差异是惊人的,值得注意的是,这个地球图片实际上是由许多许多小图片构成的,所以我们可以说在大量小文件的情况下,http/2相比http/1.1 有着令人震惊的提升。
它提高性能的提升主要有两点。
-
头部压缩
在http/1.1时期,只有请求体能够被压缩,但是有些情况下请求头因为复杂的请求字段也会变得非常大,http/2 就利用了HPACK算法对请求头进行压缩。
HPACK有以下两个亮点。
服务器和客户端之间会建立一个哈希表,存放一些常用的字段,服务器和客户端交互的时候不发字段,而只发这个字段在在哈希表中对应的索引,这实现了字段的极大压缩。
这里的字段可以包含任何字符,比如你可以把
GET放到哈希表中,也可以把index.html放到哈希表中。HPACK会对数字和字符串进行哈夫曼编码。
-
多路复用
HTTP/2 利用流在同一个TCP连接上来进行多个数据帧的通信。
在HTTP/1.1 时代,有一个很大的问题就是HTTP队头阻塞。HTTP的前一个请求如果还没有得到响应,后面的请求就会被阻塞住。要区别HTTP队头阻塞和TCP队头阻塞,前者的层次是在HTTP 请求-响应层面,而后者是数据报层面。
我们可以使用并发连接试图解决这个问题,但这只是增加了TCP链接来均摊风险,每一条链接内部仍然存在HTTP队头阻塞,所以可以说并发连接这个方案没有从根本上解决HTTP队头阻塞这个问题,只是一个缓和方案。
HTTP/2 的解决方案是二进制分帧。通过把请求和响应划分为更小的帧,在服务器看来不再是一个个完整的报文,而是一堆乱序的二进制帧,这些二进制帧不需要排队等待,直接一股脑发送即可,所以解决了HTTP队头阻塞的问题。
很显然,客户端向服务端发送请求的二进制帧,服务器向客户端发送响应的二进制帧,这种二进制帧的双向传输的序列,也叫做流。
HTTP/2 用流 在同一个TCP连接上来进行多个数据帧的通信,这就是多路复用的的概念
此外HTTP/2 还设置了一些新功能。
-
设置请求优先级
二进制帧中Priority帧作为一种控制帧可以实现设置优先级的功能。
-
服务器推送
服务器不再是完全被动的接收请求,它也能主动给客户端发送消息。比如客户端请求了一个html文件,服务器可以在返回html的基础上,把这个html引用到的其他文件比如js文件和css文件一起返回给客户端,减少客户端的等待。
23. HTTP/2 中的二进制帧是如何设计的?
这个问题可以从帧结构、流的状态变化、流的特性三个角度来回答。
帧结构
HTTP/2的 二级制的 帧结构如下图。

每个帧可以分为帧头和帧体。
帧头中一共有9个字节。前3个字节代表帧的长度【帧体的长度】。
第四个字节代表帧类型,大体分为数据帧Data 和 其他的控制帧。
这里介绍两个比较有用的控制帧。Header帧用来打开第一个流。Priority帧可以用来实现设置请求优先级。
对各种帧的介绍请参考 HTTP/2 中的帧定义
第五个字节是帧标志,共有8个标志位。比较常用的有END_HEADERS表示头数据的结束,END_STREAM表示单方面数据发送结束。
后四个字节是Stream ID,即流标识符,利用这个标识符,接收方就能从乱序的二进制帧中选择出相同ID的帧,按顺序组装成请求/响应报文。
流的状态变化
之前讲过,流是双向传输的二进制序列。而流的状态是会发生的改变的,比如流什么时候开始传输,什么时候结束。
HTTP/2借鉴了TCP状态转化的思想,借用帧的标志位来实现具体的改变。
一个普通的响应-请求的过程如下图。

首先客户端发送一个Headers帧,提醒服务端 流的传输即将开始,开始后就是双方进行双向传输 数据帧 / 控制帧。
如果客户端觉得信息获取的差不多了,打算关闭流,客户端就向服务端发送END_STREAM帧【更准确说是有END_STREAM标志位的帧】,这个时候客户端就处于半关闭状态了,只能接受,不能发送。
服务端接受到END_STREAM帧后,立刻处于半关闭状态,只能发送,不能接受,随后服务端也向客户端发送一个END_STREAM,服务器的流完全关闭。
客户端接受到服务器发送的END_STREAM帧后,流也完全关闭,这时两者都处于了关闭状态。
流的特性
-
并发性
同一个HTTP/2连接上可以同时收发多个帧,这也是实现多路复用的基础。
-
自增性
流ID不可重用,而是顺序递增,当达到上限后会新开TCP连接从头开始。
-
双向性
客户端和服务端都可以创建流,互不干扰,双方都可以作为发送方和接收方。
-
可设置优先级
可以设置数据帧的优先级,让服务器优先处理重要资源,优化用户体验。
浏览器
1. 能不能说一说浏览器缓存?
浏览器缓存可以分为强缓存和协商缓存
它们的区别是是否需要发送http请求。强缓存是不需要发送http请求的。
我们先来说强缓存。
服务器在响应头中的Expires和Cache-Control字段可以用来控制强缓存的时间。
我们拿一个实例举例子,你可以在终端里输入一下命令。
1 | |
我们可以在服务器的响应中看到两个字段。
1 | |
第一个expires表示这个内容的过期时间是在在2022年5月1号14:58分。
第二个cache-control表示这个内容可以在 14400秒内 直接使用。
看上去Expires描述的内容更加直观,写明了内容将会在什么时候过期,浏览器在这之前都可以直接强缓存,不需要重新请求。但是Expires有个很坑的地点,就是服务器的时间和客户端的时间可能是不同的。
实际上我在写这个内容的时候已经是2022年5月1号19:00了,如果按照expires的值,这个图片早就过期了,但是它仍然好好的,这是因为服务器的时间是GMT,而我的时间是GMT+8。所以这个图片真实的过期时间是我这里的 2022年5月1号22:58分
Expires由于存在明显缺陷,在HTTP/1.1中提出了Cache-Control这个字段,它没有指明具体的过期时间,而是用max-age给了一个图片可以有效的存活时间,这样就算服务器和浏览器的时区不同,浏览器仍然知道它应该在4个小时后过期此缓存。
Expires按理说应该被淘汰了,它是HTTP/1.0提出的,但是如你看到的,很多服务器还会去使用它,好在如果这个服务器同时有Expires和Cache-Control的情况下,Cache-Control会被优先考虑。这也是为什么这张图片没有过期的原因。
Cache-Control字段中不光可以写max-age来指明图片的有效存活时间,还有以下的值。
-
private
表示只有浏览器能够缓存,中间的代理服务器不能缓存
-
no-cache
跳过当前的强缓存,发送HTTP请求,直接进入 协商缓存阶段
-
no-store
直接不进行任何缓存,不强缓存也不协商缓存
-
s-maxage
它和max-age类似,但是是针对代理服务器的缓存。
再来说协商缓存
协商缓存实际上发生在强缓存失效时候。
http头部中和协商缓存两个相关的字段是Last-Modified和Etag。
比如你使用以下命令可以查看 我的博客地址返回的响应。
1 | |
你可以在响应中发现这两个字段
1 | |
而且你会发现响应中没有Expires也没有Cache-Control字段,说明我的博客页面是不使用强缓存的。
这可是由于博客文章可能会随时变化,我们无法断定在未来某个时间段之前博客页面不会变化而让浏览器强缓存了。
但是出于节省服务器流量的考虑,我的博客页面支持协商缓存。
如果服务器一开始的响应字段有Etag,那么浏览器就会在 协商缓存请求 的时候加上If-None-Match: Etag-value。
如果服务器一开始的响应字段有Last-Modified,那么浏览器就会在 协商缓存请求 的时候加上If-Modified-Since: Last-Modified-value。
服务器得到后会进行判断,查看内容是否发生了更改,如果没有发生更改,则返回 304状态码【响应体为空】表示让浏览器继续用之前的缓存吧,内容没变!如果服务器判断后发现内容改变了,则会返回200状态码,响应体则为新的内容,而且也会更新的Last-Modified和Etag的值。
Etag和Last-Modified各有优点。
Etag是对文件内容的哈希,内容一变,Etag就会变,十分准确, 但是消耗性能。
Last-Modified是服务器去看文件什么时候被编辑过了,这个时间可能不够准确【比如1秒中内修改多次服务器无法识别】。而且如果只是touch这个文件而没有实际修改内容,也会更新Last-Modified的值,这实际上不需要,因为内容没变,但是Last-Modified识别的不是文件内容,而是文件编辑时间。当然了,它的优点就是性能优异,服务器不需要进行哈希运算。
如果服务器同时返回了Etag和Last-Modified,服务器决策时会首先根据Etag来决策。
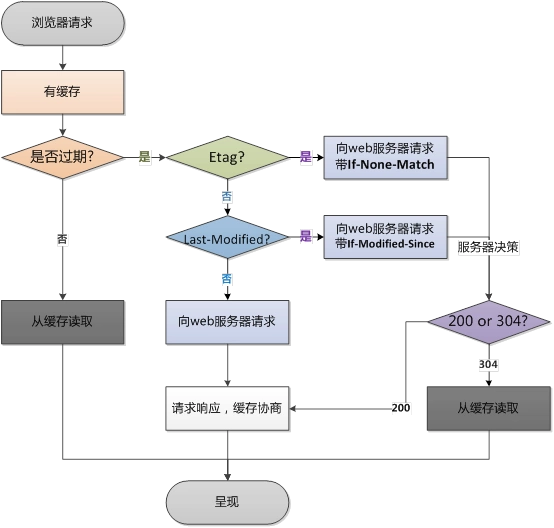
浏览器存放缓存的位置有四个。按照优先级分别是
-
Service Worker Cache
-
Memory Cache
-
Disk Cache
-
Push Cache
比较常见的就是内存缓存和磁盘缓存了,一般来说较小的文件会进入内存,较大的文件会进入磁盘缓存。
最后我又写了一个小页面来学习Cache-Control。
在线链接:https://wuuconix.github.io/static/cache-control/
页面源码:https://github.com/wuuconix/static/tree/main/cache-control/src
2. 能不能说一说浏览器的本地存储?各自优劣如何?
浏览器的本地存储主要分为Cookie,Web Storage和IndexedDB。其中Web Storage又分为localStorage和sessionStorage。
-
Cookie
Cookie一开始设计实际上不是为了做本地存储的,而是为了弥补HTTP在状态管理方面的不足。
HTTP协议是一个无状态协议,客户端向服务端发送请求,服务端响应,就ok了。那如何让服务器根据不同的客户端发送具有特点的响应呢?这个背景下就产生了Cookie,服务器端会解析客户端请求携带的cookie,得到客户端所处的状态,从而返回具有不同的响应。
然而Cookie存在很多缺陷。
-
容量缺陷。Cookie的体积上限是4KB
-
性能缺陷。Cookie和一个域名绑定在一起,访问这个域名下的任意路由都会在请求中携带Cookie而不管这个路由到底需不需要Cookie。当请求数较多时,对性能是非常浪费的。
值得注意的是,如果是域名下的一个具体的文件。比如 https://yun.139.com/w/static/js/jquery.min-1.11.1.js 则不会包含cookie。
-
安全缺陷。Cookie以纯文本的形式在浏览器和服务器之间传递,很容易被黑客截获。
-
-
localStorage
localStorage有一点和Cookie一样,就是一个域名下面对应一个localStorage。
但是它相比cookie有以下好处。
-
容量。localStorage的容量上限为5MB。相比4KB的Cookie大了许多。
-
只存在于客户端,默认不参与客户端和服务端的通信,这样就很好避免了Cookie带来的性能问题和安全问题。
-
接口封装。利用localStroage.setItem 和 localStorage.getItem等方法可以方便的进行操作。
1
2localStorage.setItem("wuuconix", "yyds")
localStorage.getItem("wuuconix") //yyds
localStorage适合存储一些内容稳定的资源。
-
-
sessionStorage
sessionStorage和localStorage几乎一致。它们唯一的区别是前者为会话级别的存储。而后者是持久存储。会话结束,即页面关闭后,sessionStorage就没了。
页面的刷新不会导致sessionStorage消失(包括硬刷新)。只有关闭页面后sessionStotage才会消失。而且同域名,不同页面下由于是不同的会话,它们的sessionStorage不共享。所以sessionStorage的存储只限当前页面,页面一关就会消失。
由于sessinStorage刷新后不消失,我们可以用来将表单信息保存在其中,在用户不小心刷新页面后仍然能够恢复。
-
IndexedDB
它是运行在浏览器上的非关系型数据库。理论上容量无上限。
IndexedDB除了数据库本身的特性,比如支持事务、存储二进制数据等。它还有一些特性。
-
键值对存储。
-
异步操作。
-
受同源策略限制,无法访问跨域的数据库。
它唯一的缺点可能就是操作太复杂了。根据mdn的推荐,我们可以使用localForage这个indexDB封装库来用简单的api使用indexDB,降低编程难度。
最后我写了一个页面来尝试在IndexDB中存储20张图片。
第一次访问网站需要等待20个图片的fetch。
之后进入网站就是直接从IndexDB里面取图片了。
在线链接:https://wuuconix.github.io/static/IndexDB/
页面源码:https://github.com/wuuconix/static/tree/main/IndexDB/src
-
3. 说一说从输入URL到页面呈现发生了什么?(网络)
-
浏览器构建请求
实际上就是HTTP报文中的起始行。包括 请求方法 路径 HTTP协议版本
1
GET /%E5%9B%BE%E5%BA%8A/image-20220320212359433.png?download=1 HTTP/1.1 -
查找强缓存
如果命中,不需要发送HTTP请求,直接使用浏览器中的强缓存。如果没有命中则进入下一步。
-
DNS解析
查看浏览器中有没有该域名的DNS解析缓存,如果有,则直接根据缓存结果得到该域名的ip,如果没有缓存,则请求DNS服务器得到该域名的ip。
-
建立TCP连接。
需要三次握手建立起客户端和服务器之间的连接。
-
发送HTTP请求
当TCP连接建立完毕,浏览器就可以向服务器发送HTTP请求。HTTP请求包括请求行【即第一步里建立的起始行】、请求头,如果是POST请求的话还会有请求体。
-
服务器HTTP响应
响应报文中包含相应行、响应头和响应体。
响应行由 HTTP协议版本 状态码 和 状态描述组成。
1
HTTP/1.1 302 Moved Temporarily响应结束后TCP连接不一定结束,需要看HTTP请求头或者响应头中是否包含
Connection: Keep-Alive,如果有,则表示建立了持久连接,之后的HTTP请求都会复用这个TCP连接。如果是
Connection: Close,请求响应流程结束,需要关闭TCP连接。TCP需要4次挥手,从而关闭TCP连接。
最后附上一张图。
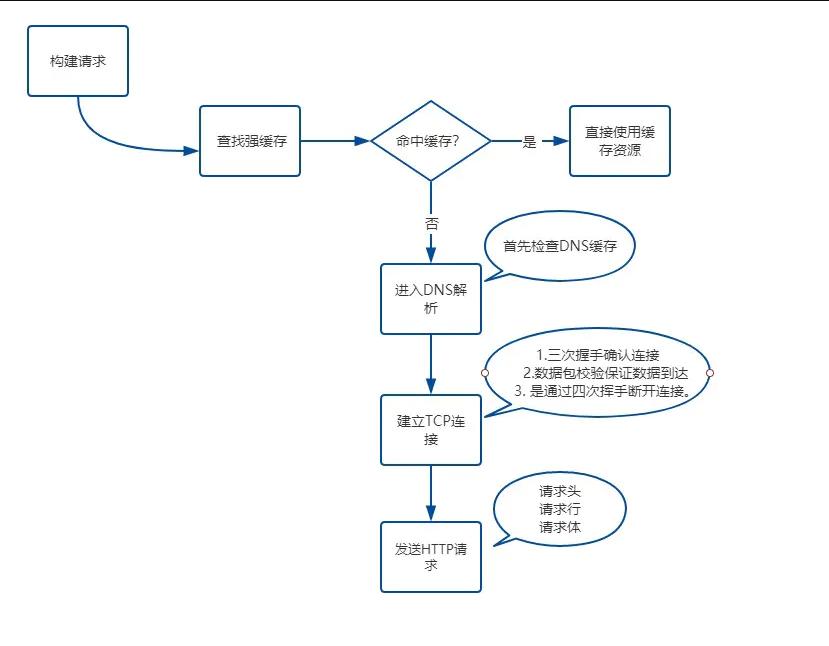
4. 说一说从输入URL到页面呈现发生了什么?(解析算法)
在完成了网络请求和响应后,如果响应头的Content-Type为text/html,那么接下来就是浏览器的解析和渲染工作。
解析主要分为
-
构造DOM树
由于浏览器无法理解HTML字符串,所以需要解析为DOM树。
解析算法主要包括了标记化算法和建树算法。
-
样式计算
-
格式化样式表。我们可以用
document.styleSheets查看结果。 -
标准化样式属性。比如说把red变成#ff0000等。
-
计算每个节点的具体样式。规则是继承和层叠。最终某个节点的样式结果我们可以用
window.getComputedStyle(document.querySelector("#subtitle"))来得到。
-
-
生成 布局树
Layout Tree在有了DOM树和DOM样式,现在我们就需要确定各个元素的位置,也就是生成一颗布局树。
布局树的大致工作如下:
-
遍历DOM树的节点,把它放到布局树中
-
计算布局树的节点的坐标位置
值得注意的是布局树中仅包含可见元素,比如head标签和设置了
display: none的元素,将不会放入其中。所以display: none的元素在DOM树里,但是最终不会出现在布局树中,所以最后它将不占页面的位置【甚至你用浏览器开发者工具的元素审计你只能看到它在DOM中,但是鼠标移动它上面,页面上不会有任何显示,因为它不存在于布局树中】 -

5. 说一说从输入URL到页面呈现发生了什么?(渲染过程)
绘制图层树
在4. 说一说从输入URL到页面呈现发生了什么?(解析算法)我们已经得到了布局树,看起来貌似我们已经能够直接开始绘制了,但是实际上还不行,因为css中有一个属性z-index将导致层叠上下文的出现。
这些层叠上下文将可能导致元素之间被遮盖等很多问题。所以我们还需要生成一颗 图层树 Layer Tree来对布局树中的特定节点进行分层。
节点的图层默认属于父节点的图层【这些图层被称为合成层】,但是有两种情况会导致被提升作为一个单独的合成层。
第一种情况是显式合成。
-
拥有层叠上下文的节点会触发显式合成,至于如何拥有层叠上下文,参照MDN层叠上下文
-
需要被裁剪的地方。比如一个div很小,但是里面有许多文字,那么超出的文字就会被裁剪。不光如此,如果出现了滚动条,滚动条也会被单独提升为一个图层。
第二种情况是隐式合成
如果一个层叠等级低的节点被提升为单独的图层之后,那么所有层叠等级高比它高的节点都会成为一个单独的图层。
隐式合成隐藏着巨大的风险,特别是在大型应用当中,一个z-index较低的元素被提升为单独节点之后,可能会增加上千个图层,大大加大内存的压力,让页面崩溃,这就是层爆炸的原理。
生成绘制列表
即根据图层树,生成绘制指令,得到一个绘制列表。
生成图块和生成位图
当绘制列表生成完毕之后,主线程会向合成线程发送commit信息,并它绘制列表传递给它。
由于视窗的大小相对固定,而页面有时候可能很大,如果一口气全部绘制,将相当浪费性能。所以为了节约性能,合成现成首先会对图层进行分块。
合成线程会把视窗附近的图块交给栅格化线程池,让它把图块转化为位图,实际上这个转化的过程会使用GPU进行加速,最后位图的结果会发送给合成线程。
显示器显示内容
栅格化操作后【即生成了位图】,合成线程会发送一个绘制指令,发送给浏览器线程,浏览器线程会绘制到内存种,然后交给显卡,从而最后显示到显示器上。

6. 谈谈你对重绘和回流的理解
以下内容我们将基于前两个问题。
我们在得到HTTTP响应后,页面的呈现经过了以下的步骤。
构建DOM树 -> 计算样式 -> 生成布局树 -> 生成图层树-> 构建绘制列表 -> 生成图块和位图 -> 显示器显示
首先先讲讲重绘。
重绘的触发条件是 DOM的样式修改了,但是几何属性没有改变。这意味着我们可以不用重新构建DOM树,也不用重新生成布局树和图层树,因为几何属性没有变。
所以重绘只需要 计算样式 -> 构建绘制列表 -> …
再讲讲回流。
回流又叫做重排。它的触发条件是DOM的几何属性发生了变化。
具体一点的话,以下操作会触发回流。
-
DOM元素css样式中的几何属性发生变化,比如width,top,border等。
-
DOM节点发生了增减或者移动
-
读写offset,scroll,client族属性的时候,浏览器为了获得这些值,需要进行回流的操作。
-
调用window.getComputedStyle方法
由于回流被触发的时候,DOM树、布局树、图层树都可能发生了改变,所以我们必须把 解析 和 渲染的过程全部重新执行一遍。
除了重绘和回流,实际上还有一种情况,就是直接合成。
相当于我们将直接跳到 合成线程那里,相比重绘,我们不用计算样式,不用重新构建绘制列表,而直接与合成线程交流实现合成的效果,这实际上就是GPU加速
直接交给合成线程有两大好处。
-
充分发挥GPU的优势,由于合成线程会调用栅格化线程池,并使用GPU来加速生成位图,而GPU是擅长处理位图数据的。
-
没有占用主线程的资源,因为合成线程属于非主线程,所以就算主线程卡住了,效果依然能够展示。
在了解了 重绘、回流和直接合成之后,我们需要记住以下的最佳实践。
-
避免频繁使用style,才是采用修改class的方式
-
采用createDocumentFragment来批量进行DOM操作
-
对于resize、scroll等进行防抖/节流操作
7. 能不能说一说XSS攻击?
XSS的全称是Cross Site Scripting。为了和CSS区分故称为XSS。
XSS攻击是指在浏览器中执行恶意脚本(无论是跨域还是同域),从而拿到用户的信息。
XSS一般可以可以完成以下事情。
我写了一个页面来遭受XSS攻击的页面。
-
窃取Cookie
1
https://wuuconix.github.io/static/xss/?q=<img src=x onerror="alert(document.cookie)"> -
修改DOM伪造登录表单
1
http://localhost:8080/?q=<div><form><label for="user" style="display: inline-block; width: 70px">用户名</label><input id="user" style="display: inline-block; width: 150px"><br><label for="pass" style="display: inline-block; width: 70px">密码</label><input id="pass" style="display: inline-block; width: 150px"><br><input type="submit" style="display: block; margin-left: 50%; transform: translateX(-50%); margin-top: 10px" onclick="alert('你的用户名和密码已被黑客获得')"></form></div> -
在页面中生成浮窗广告
1
https://wuuconix.github.io/static/xss/?q=<div style="position: relative; text-align: center;" onclick="window.location.replace('https://wuuconix.link')"><img style="width: 50vw" src="https://sina.wuuconix.link/large/007kZ47kgy1gqizz0ipr0g30f008f7wj.gif" ><span style="display: block; width: 100%; font-size: 32px; text-align: center; position: absolute; top: 50%; transform: translateY(-50%); color: white; user-select: none">点击查看更多美女</span></div>
实际上XSS的作用就是在当前页面中执行了一段恶意JS代码,考虑到JS几乎啥都能干,该页面的DOM树可能被任意修改,网页外观大变样,充斥着各种广告,不光如此,XSS完全能够利用js监控你页面上的账号密码,让你没有任何隐私而言,得到cookie更是小菜一碟。XSS能造成的危害真的可能非常大,而不光是我们平常了解的一个alert。
XSS大致可以分为反射型和存储型。
反射型XSS是将恶意脚本作为了网络请求的一部分,就像刚才三个链接一样,恶意脚本是query的值,我写的那个页面实际上就是把用户输入的q变成了一个div的innerHTML,从而让DOM结构发生改变,实现XSS注入。
反射型XSS较为明显,因为它的恶意代码在url中,如果有一点网络知识的人就能轻松看出来。
存储型则更为恐怖,直接把恶意脚本存储在了服务器上,用户看上去完全正常的网络请求仍然会执行恶意代码。
XSS的防范措施
-
千万不能相信用户的输入,无论在前端和后端,都需要对用户的输入进行转码或者过滤。
前端可以通过一个巧妙的方法实现转码。我们都知道HTML中引号,小于号这些都是有它们特定的作用的,如果我们想在文本中没有副作用地使用这些特殊字符,可以把它们为HTML实体字符,比如双引号就是
",小于号就是<。所以我们在防范XSS的时候可以把用户输入的各种特殊字符转化为HTML实体字符,最后页面渲染出来的还是正常的字符,但是它们已经失去了HTML中特定的功能。
而且在前端有个方便的方法用来实现这种特殊字符的转码,即利用
innerText和innerHTML。1
2
3
4
5
6
7let htmlspecialchars = (str) => {
let div = document.createElement("div")
div.innerText = str //设置innerText后再读取innerHTML,结果会把引号,尖括号等元素变成html实体
str = div.innerHTML
div = null //希望能触发垃圾回收机制
return str
}试试在刚才的三种模拟攻击的url加上
encode=1。 -
利用CSP
Content-Sucurity-Policy,它是浏览器中的内容安全策略。我们可以用CSP来设置浏览器可以加载那些资源。开启CSP可以让服务器的响应的头部中加入
Content-Security-Policy字段。当然还有更方便的方法,我们可以在前端页面的
<meta>标签中开启它。1
<meta http-equiv="Content-Security-Policy" content="default-src 'self'">该配置会让浏览器只获取此域名下的文件。正常的外链图片都会完全失效,因为违反了安全策略。
尝试在之前的三种攻击中加上
csp=1吧。CSP能干的事情还有很多,比如在疑似XSS攻击【即违反了我们设置的策略】发生的情况上访问某个url实现上报。
更多CSP设置参考Content Security Policy 入门教程
-
设置HttpOnly
设置HttpOnly后会让JS无法获取到Cookie,避免了那些专门获取Cookie的XSS。实际上比较局限,因为ss能干的,可不仅仅是获取Coolie。
HttpOnly需要后端配置,前端无法自行实现。
8. 能不能说一说CSRF攻击?
CSRF Cross-Site Request Forgery 跨站请求伪造。
CSRF和XSS有明显区别,XSS是在某个正常页面中执行恶意代码,而CSRF是在一个恶意网站里通过一些手段跨站请求正常网站,因为正常网站有cookie等持久化存储手段,用户仍然处于登录状态,所以恶意网站就可以以正常用户的名义执行一些恶意操作。
这里有一个CSRF例子。什么是CSRF?
它的情景是一个银行api,用户访问这个api后就可以向别人转钱,由于此api缺少验证,黑客利用CSRF把受害者的钱转到自己的账户上。
由于恶意代码是存在黑客自己的页面上,所以它相比于XSS有着无比的自由,因为黑客可以任意的编写页面。
如果黑客已经通过一些广告策略让许多用户到达了自己的页面,现在要实现用户一访问此页面就发送某个跨站请求可以如何实现呢?
Get请求我们可以这样干
1 | |
页面一加载就会去试图请求此图片,但实际上这个图片的src就是一个跨站请求。
至于Post请求,我们可以写一个自动提交的Form表单
1 | |
我写了一个模拟CSRF页面。为了方便,我在页面的右下角设置了一个浮动广告,点击后就能到达黑客的恶意页面。恶意页面会发起跨站请求,你一点击应该就能看到效果了。😃
在线预览:https://wuuconix.github.io/static/csrf/
源码链接:https://github.com/wuuconix/static/tree/main/csrf/src
防范CSRF的措施
说实话我觉得现在CSRF的破坏性不是很大,因为现在的绝大部分接口都是非常复杂的,不是简单的一个url就能请求成功。
-
利用Cookie的SameSite属性
设置SameSite为Strict。这样第三方的请求将不会带上Cookie,黑客也就无法构造出一个有用的跨站请求了,因为没有携带cookie就意味着用户处于登出状态。
-
验证来源站点
可以查看请求头的Origin和Referer。前者包含请求来自的域名,后者则包含具体的URL路径。
然而这两者可以被伪造,安全性略差。利用Fetch自定义请求头应该可以实现伪造。
-
CSRF Token
浏览器如果要发送请求必须带上这个CSRF Token,通常第三方站点无法得到CSRF Token,就会被服务器拒绝。
9. HTTPS为什么让数据传输更安全?
HTTP是明文传输的,它在传输过程中可能会遭遇中间人攻击。
然后HTTPS便在HTTP层和TCP加了一个中间层,也叫做安全层,安全层的核心就是加解密。
HTTPS的加解密运用了对称加密和非对称加密结合数据签名认证的方式。
以下是整个流程
-
浏览器向服务器发送一个client_random和加密方法列表
-
服务器收到后返回server_ramdom, 加密方法和数字证书
这个数字证书中包含了公钥
-
浏览器验证数字证书,如果验证通过,则继续。
-
浏览器生成另一个随机数pre_random,并且用公钥加密,发送给服务器
-
服务器利用私钥解密这个被加密后的pre_random,得到pre_number
-
服务器根据之前选择的加密方法,利用client_random, server_random和pre_random共同生成secret,这就是最终的密钥,服务器生成后发送给浏览器一个确认
-
浏览器接受到确认后,也用同样的加密方法得到secret。
-
之后浏览器和服务器就用同样的密钥secret进行对称加密。
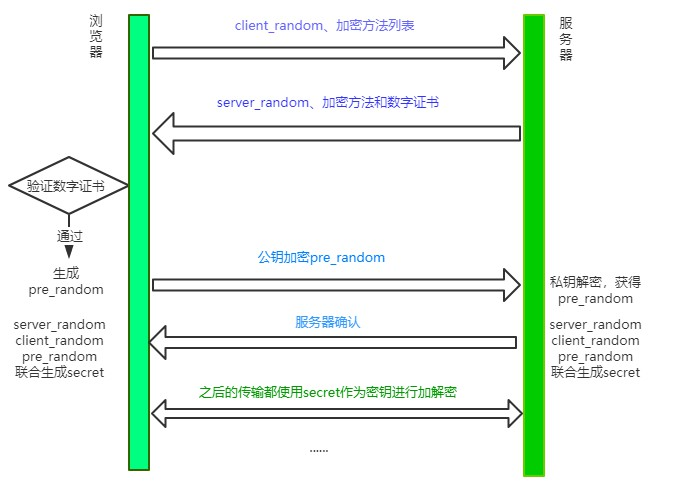
10. 能不能实现事件的防抖和节流?
防抖和节流的本质上是对高频率执行代码的一种优化手段。
比如浏览器的resize,scroll,keypress,mousemove等事件在触发时,会不间断地调用绑定的回调函数,极大地浪费资源,降低前端性能。
节流:n秒内只执行一次,若在n秒内重复触发,只有一次生效。
防抖:n秒后再执行该事件,若在n秒内被重复触发,则重新计时。
节流代码1 利用setTimeout
1 | |
值得注意的是,节流函数返回的是一个函数。所以我们需要这样来调用它。
1 | |
节流代码2 直接判断时间戳
1 | |
然后是防抖的代码。防抖的突出特点是如果重复触发,那么计时器会重置。
防抖代码
1 | |
值得注意的是,如果在防抖情况下,如果一直重复触发,那么用户很可能会一直无法得到想要的结果,所以这里提出了一个加强版防抖 或者说加强版节流,实际上就是把防抖和节流的结合起来,以解决防抖导致的一次响应也没有的问题。
防抖-节流结合代码
1 | |
在事件非常频繁的时候,它的效果和正常的节流代码实际上是一样的效果,因为特别频繁的时候,计时器会被一直归零,然后每次响应都是超时那部分代码调用的,所以和节流效果一致了。所以个人感觉这种结合的方式没有什么特别亮眼的地方。
我还是写了一个页面,页面的主要内容是4个按钮,分别是正常点击、节流点击、防抖点击、节流防抖结合点击,你可以尝试点击它们查看不同的效果 😃
在线预览:https://wuuconix.github.io/static/throttle-debounce/
源码链接:https://github.com/wuuconix/static/tree/main/throttle-debounce/src
11. 能不能实现图片懒加载?
如果我们要手动实现的话,实际上思路非常简单,首先,我们将所有的图片都设置为一个默认的图片源,看后检测滚动信息,当图片出现在在用户的视图中的时候,我们就把图片的src设置为真正的图片源。
为了确定图片是否在用户的视图中,我们需要了解以下一些变量。
1 | |
然后我们如何判定一张图片在浏览器的视图中呢?我们考虑进入视图和离开视图这两种边界情况。
我们在滚动页面的过程中,图片会不断往上运动,一开始图片的上界等于视图下界的时候,图片就相当于进入了,然后图片的下界等于视图上界的时候,就是要离开了。
所以判断的条件应该类似这样
1 | |
还有一种更加方便的做法是调用imgEle.getBoundingClientRect().top
它将返回图片的上界相对于浏览器视图的相对坐标,比如它顶着视图上界,那么就是0。
同样根据之前的思想,我们可以将判断条件更改为
1 | |
更加简单了对吧?值得注意的是,前这两种方法我们都是手动判断每个图片是否在视窗中,还需要绑定scroll事件,每次scroll的时候都需要判断,然后还需要加入节流或者防抖来提高性能。
接下来介绍的方法,利用了IntersectionObserver观察器,它帮我把监听scroll,判断是否在视窗中,以及节流全部做了。
具体的使用方法类似下面。
1 | |
看起来很方便对吧?但是我在实际使用的时候遇到一点感觉不好的地方,因为它帮我们做了节流,而在有一些图片非常多的情况下,用户快速的从一开始滑动到结尾,如果是节流,在滑动的过程中会让一些图片响应,从而改变图片,而我认为这种情况下实际上不需要加载出来的,因为用户这么快速的滑动,很显然是只想看末尾的图片,所以我认为这种情况下用防抖更好,而IntersectionObserver貌似只能是节流,而不能是防抖。
而且它的节流效果约等于0,一路滑下来,所有的图片都变了:(
个人建议还是自己写吧,自由度高一些。
同样的,我写了一个懒加载页面,里面有100张图片,采用防抖方式,用户停止滚动0.2秒后,视图内的图片的源会被替换成它真正的源。
在线预览:https://wuuconix.github.io/static/lazyload/
源码链接:https://github.com/wuuconix/static/tree/main/lazyload/src
TCP
1. 能不能说一说 TCP 和 UDP 的区别?
TCP: Transmission Control Protocol
UDP: User Datagram Protocol
概括来说,
-
TCP是 面向连接的,可靠的,基于字节流的传输层协议。
-
UDP是 面向无连接的,不可靠的,基于数据包的传输层协议。
具体来说,和UDP相比,TCP有三大核心特征。
-
面向连接的。所谓连接,就是客户端和服务端的连接,在双方通信之前,TCP需要三次握手建立连接,而UDP则没有建立连接的过程。
-
可靠性。TCP的可靠性体现在 有状态 和 可控制。
-
TCP会精确记录哪些数据发送了,哪些数据被接受了,哪些没有被接受,而且保证数据按需到达,不允许半点差错,这就是有状态。
-
当意识到丢包了或者网络环境不佳,TCP就会自动调整自己的发送速度或者重发。这是可控制。
-
-
面向字节流。
UDP的数据传输是基于数据报的,这实际上仅仅是因为它继承了IP层的特性,因为IP数据报是数据报
IP Datagram。而TCP为了维护状态,将一个个IP报变成了字节流。
2. 说说 TCP 三次握手的过程?
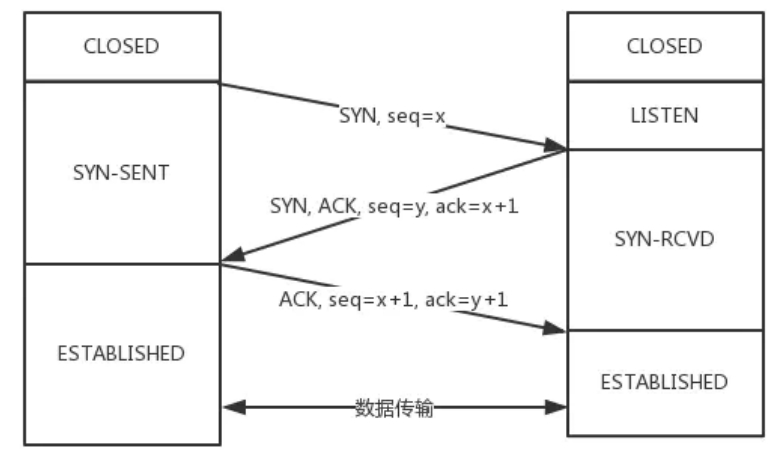
-
首先服务器已经处于Listen状态,客户端还处于Closed状态。
-
客户端主动发起连接,发送SYN,自己变成了SYN-SENT状态。
-
服务端收到,发挥SYN和ACK(这个ACK对应客户端发来的SYN),自己变成SYN-RCVD。
-
之后客户端再发送ACK给服务端,自己变成了Established状态,服务端收到ACK后也变成了Estabilished状态。
TCP的三次握手实际上是为了需要确认双方的两样能力:发送的能力和接受的能力。
而客户端一开始的SYN证明了自己发送的能力,服务器的的响应,证明了自己发送和接受的能力,最后客户端回应,证明了客户端接受的能力,这个时候,两个已经证明了自己发送和接受的能力,两者便可以开始数据传输了。
3. 为什么是三次而不是两次、四次?
为什么不是两次
根本原因是因为无法确认客户端的接受能力。
下面是一个例子。
客户端发送一个SYN包给服务端,但是包滞留在了当前网络中迟迟没有到达,TCP的重传机制会导致重传,重传后服务端响应,连接就建立了,目前都没有什么问题。
现在连接关闭了,那个滞留的包又到达了服务端,服务端以为客户端又要建立连接了,于是响应,建立了连接,但是实际上客户端已经断开了,客户端不会发送任何数据,而服务端就是等在那里,浪费了连接资源,这里就是因为两次握手导致的无法确认客户端是否具有接受能力,从而导致的连接资源浪费。
为什么不是四次
可以是四次,但是没有必要。因为握手的目的是为了检测客户端和浏览器的 发送和信息的能力,而三次握手后双方已经向对方证明了自己的能力,所以三次就够了,四次握手只会浪费资源。
4. 三次握手过程中可以携带数据么?
第三次握手的时候可以携带数据,前两次握手不可以携带数据。
因为第三次握手的时候,客户端已经处于了Estabilished状态,并且已经能够确认服务器的接受和发送能力了,相对安全,所以可以携带数据。
前两次不行,因为可能会导致攻击,比如黑客在第一个握手的SYN报文中放大量数据,这个时候服务器势必会消耗更多的时间和内存空间去处理这些数据,增大了服务器被攻击的风险。
6. 说说 TCP 四次挥手的过程
-
首先服务器和客户端都处于Estabilished状态。
-
客户端向服务器发送Fin包,进入Fin_Wait-1状态。
-
服务器接受到Fin包,发送Ack,进入就Closed_wait状态。
-
客户端接受到Ack后,进入Fin_Wait_2状态。
-
服务器发送Fin包和Ack包,进入Last_Ack状态。
-
客户端接受到后,发送Ack包,进入Time_wait状态。
-
服务器接受到最后的Ack包后,进入Closed状态。
-
客户端在Time-Wait状态需要等待足够长的时间,具体来说是2个MSL Maximum Segment Lifetime 最大报文生存时间。如果这段时间内客户端都没有接受到服务器的的重发请求,那么表示ACK成功,挥手结束,否则客户端需要重发ACK。
等待2MSL的意义
-
1个MSL确保四次挥手中主动关闭方最后的ACK报文能够到达对端。
-
1个MSL确保对端没有收到ACK重传的Fin报文可以到达。
实际就是等客户端是否会因为没有接受到ACK而重发,而服务器如果真的重发,到客户端这里的时侯的时间小于2MSL,而等待2MSL则后仍然没有收到服务器的重传,则证明ACK真的到达了服务端。
7. 为什么是四次挥手而不是三次?
和三次握手相比为什么多出来一次手呢?因为服务器在收到客户端的Fin包后先给一个ACK表示收到,延时一段时间后才会发送Fin包,这就造成了4次挥手。
如果我们换成3次挥手,也就是服务端的Ack和Fin包合并了,由于服务端发送Fin包之前必须要等待服务端的所有报文全部发送完毕,所以可能会等很久才能一起发送Ack和Fin包。这时长时间的延时可能会让客户端误以为Fin包没有到达服务端,从而客户端会不断的传递Fin包,产生资源的浪费。